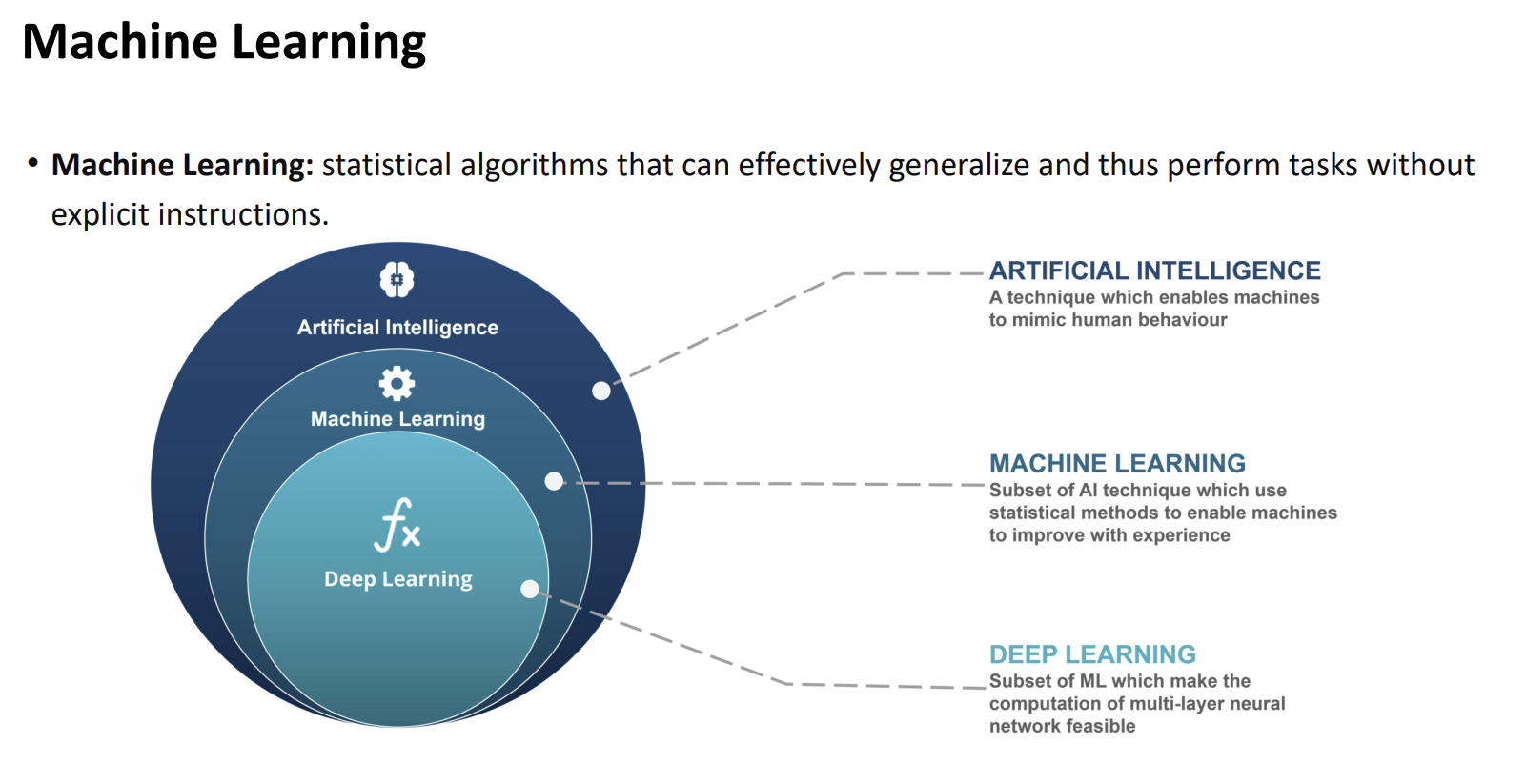
AI란 컴퓨터가 인간의 지능을 흉내내는것
머신러닝이란 AI에 하나의 분야로 데이터로부터 일반화를 시켜서 패턴을 파악하고 AI를 학습시키는 통계적인 알고리즘(전략, 방식)
딥러닝이란을 그 머신러닝의 일부분으로 Deep Neural Network을 이용하여 더 깊은 사고를 하는 도구(기술, 로직)
참고) 머신러닝과 딥러닝 구분
1. 머신러닝: 학습의 '지도'이자 '전략'
머신러닝은 "컴퓨터를 어떻게 학습시킬 것인가?"에 대한 거대한 방법론의 집합입니다.
- 학습 전략: 정답을 줄지(지도), 스스로 찾게 할지(비지도), 보상을 줄지(강화) 결정하는 규칙입니다.
- 해결 과제: 이 전략을 통해 무엇을 얻고 싶은지(분류, 회귀, 군집화 등)를 정의하는 단계까지가 머신러닝의 개념적 영역입니다.
2. 알고리즘: 전략을 실행하는 '전통적 도구들'
정의된 전략을 실제로 구현하기 위해 사용하는 수학적 수단들입니다.
- Decision Tree, k-NN, SVM: 특정 학습 전략(주로 지도 학습)을 위해 만들어진 고전적이고 강력한 도구들입니다.
3. 딥러닝: 전략을 실행하는 '가장 강력한 최신 도구'
딥러닝은 머신러닝이라는 전략을 수행하기 위해 꺼내든 가장 고도화된 엔진입니다.
- 구조적 특징: 인공 신경망이라는 뉴런 계층을 아주 깊게 쌓아 올린 형태입니다.
- 범용성: 이 엔진(도구)은 워낙 강력해서 지도 학습 전략에 장착하면 '지도 딥러닝'이 되고, 비지도 학습 전략에 장착하면 '비지도 딥러닝'이 되는 것입니다.
결론: 머신러닝은 그냥 방법론이것뿐 그걸 실현하기위해 다양한 수학적 도구들이 존재하는데 그중 하나가 (Decision Tree, k-NN, SVM 등등) 혹은 딥러닝인것뿐이다
머신러닝 (Machine Learning)
'컴퓨터가 어떤 형태의 데이터를 가지고, 어떤 방식으로 학습할 것인가'에따른 머신러닝의 4종류
Supervised(지도학습) - 정답(Label)을 통해 미래의 값을 예측/분류
Unsupervised(비지도학습) - 특징 발견(Clustering)을 통해 데이터 가 관계를 파악
Semi-supervised (준지도 학습) - 지도 학습과 비지도 학습을 합친 하이브리드 방식
Reinforcement(강화학습) - 보상(Reward)를 주는 방식으로 최적의 행동을 결정
| 구분 | 지도 학습 | 비지도 학습 | 준지도 학습 | 강화 학습 |
| 데이터 | 모두 정답 있음 | 정답 없음 | 일부만 정답 있음 | 데이터 없음(보상 기반) |
| 핵심 목표 | 예측 및 분류 | 데이터 구조 파악 | 데이터 부족 해결 | 최적 행동 결정 |
1. 지도학습
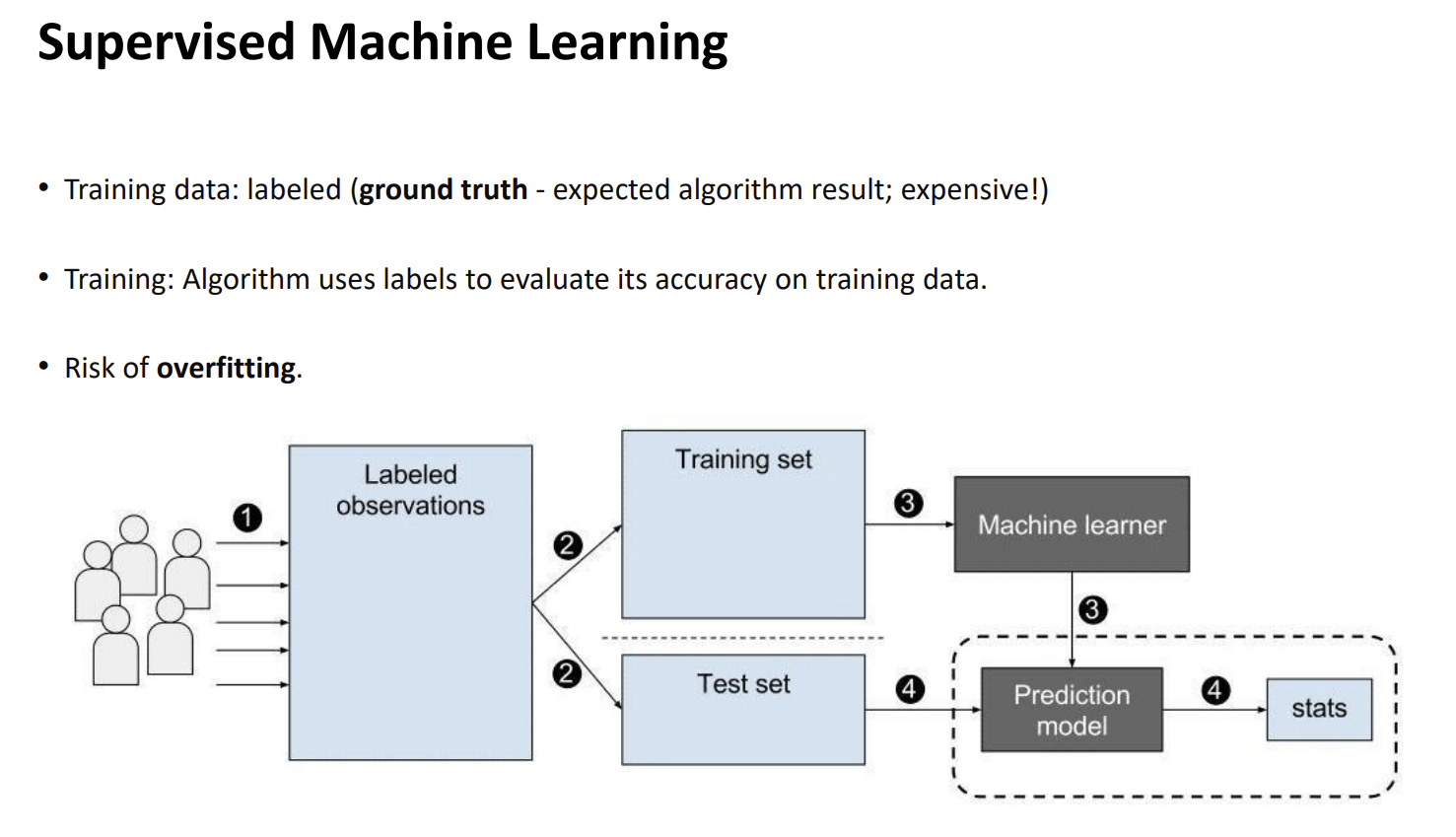
학습 데이터의 핵심: Labeled Data (정답지)
-
- Ground Truth: 인공지능이 정답이라고 믿어야 하는 '실제값'을 의미합니다. 예를 들어 고양이 사진에 "이것은 고양이"라고 적힌 태그가 바로 Ground Truth입니다.
- Expensive: 이미지 설명에 적혀 있듯, 사람이 일일이 정답을 달아야 하므로 데이터 구축에 비용과 시간이 많이 듭니다.
- 데이터 수집 (1번): 정답이 포함된 관측 데이터(Labeled observations)를 모읍니다.
- 데이터 분할 (2번): 수집한 데이터를 두 덩어리로 나눕니다.
- 학습 데이터(Training set): 모델이 공부할 때 사용하는 문제집입니다.
- 테스트 데이터(Test set): 모델이 공부를 마친 후 실력을 확인하는 기말고사입니다. (학습에 사용되지 않은 데이터여야 공정한 평가가 가능합니다.)
- 모델 학습 (3번): 머신러닝 알고리즘(Machine learner)이 학습 데이터를 보고 정답을 맞히는 규칙을 찾아내어 예측 모델(Prediction model)을 생성합니다.
- 성능 평가 (4번): 완성된 모델에 테스트 데이터를 넣어 예측값과 실제 정답을 비교합니다. 여기서 나온 결과가 통계 데이터(stats)가 되어 모델의 정확도를 판단하게 됩니다.
지도 학습에 주의사항: 과적합 (Overfitting)
-정답을 주면서 학습하기떄문에 정답을 아예 외워버리는 경우가 발생함

회귀 (Regression): "연속적인 숫자 예측"
- 목표: 수치형(Numerical) 또는 연속적(Continuous)인 값을 예측합니다.
- 특징: 그래프에서 데이터 포인트들의 추세를 가장 잘 나타내는 선(Model)을 찾는 것이 핵심입니다.
- 예시: 선형 회귀(Linear Regression), 비선형 회귀(Nonlinear Regression) 등이 있으며, 주가 예측이나 기온 예측 등이 해당합니다.
분류 (Classification): "이산적인 카테고리 결정"
- 목표: 범주형(Categorical) 또는 이산적(Discrete)인 값을 예측합니다.
- 특징: 서로 다른 그룹(Class A, Class B)을 나누는 결정 경계(Decision Boundary)를 찾습니다.
- 알고리즘: 나이브 베이즈(Naive Bayes), SVM(Support Vector Machines), 로지스틱 회귀(Logistic Regression) 등이 대표적입니다.
- 참고: 의사결정 나무(Decision Tree), 랜덤 포레스트(Random Forest), k-NN, 신경망(Neural Networks) 같은 알고리즘은 회귀와 분류 문제를 모두 해결할 수 있는 강력한 도구들입니다.
2. 비지도학습
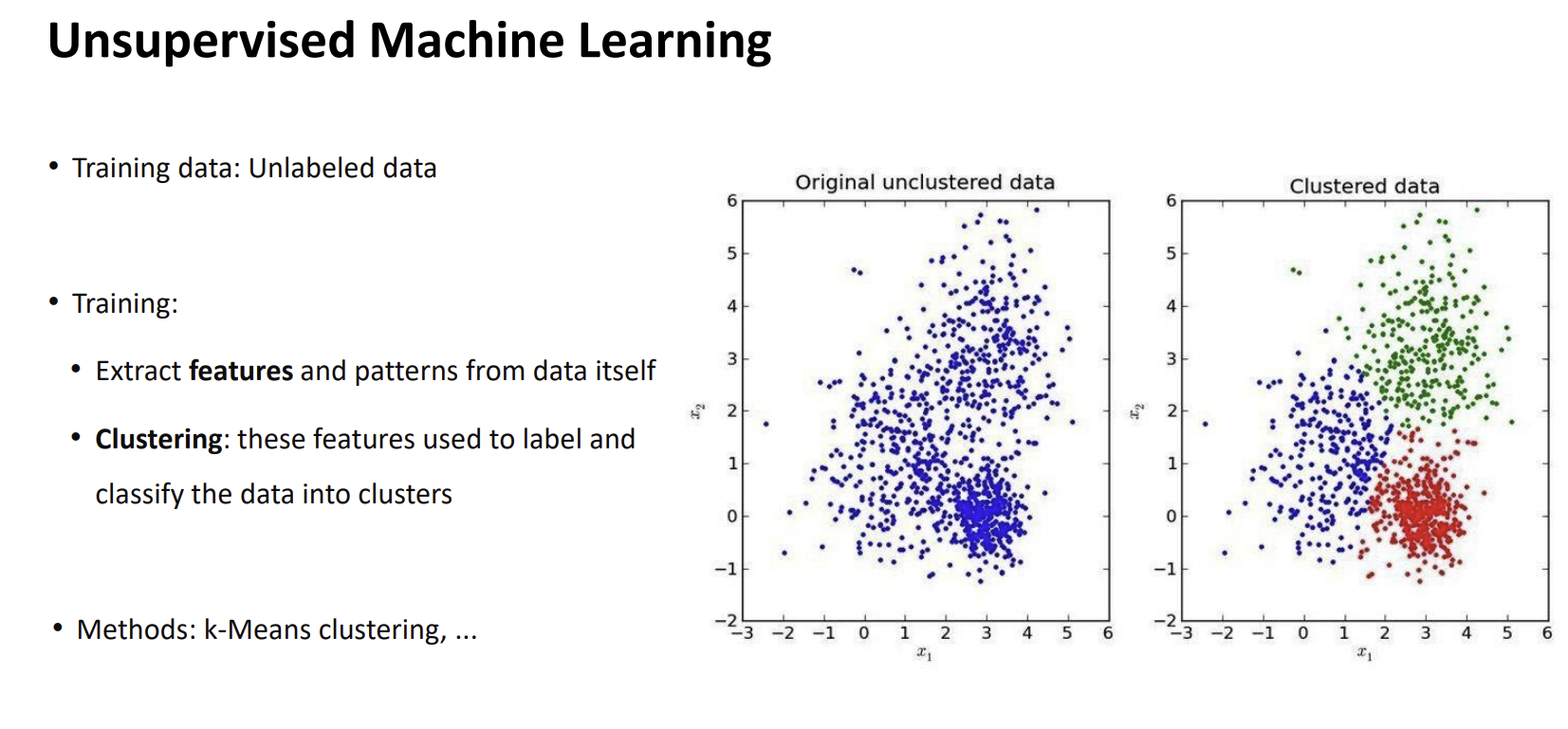

- 데이터의 특징: 정답이 달려 있지 않은 레이블 없는 데이터(Unlabeled data)를 학습 데이터로 사용합니다.
- 학습 방식: 컴퓨터가 스스로 데이터 사이의 관계를 분석하여, 데이터 자체에서 특징(Features)과 패턴을 직접 추출해냅니다.
- 핵심 목표: 데이터 속에 숨겨진 구조나 규칙을 찾아내는 것입니다.
군집화 (Clustering)
비지도 학습의 가장 대표적인 방법이 바로 군집화입니다.
- 정의: 추출된 특징들을 사용하여 데이터를 비슷한 성격끼리 묶어 그룹(Cluster)을 만드는 과정입니다.
- 그래프 설명:
- Original unclustered data : 정답이 없어 모두 똑같은 파란 점으로 보이는 상태입니다.
- Clustered data : 컴퓨터가 데이터의 거리를 계산하여 서로 가까운 것들끼리 빨강, 초록, 파랑의 세 그룹으로 분류해낸 결과입니다.
- 대표적인 알고리즘: 이미지에 언급된 k-평균 군집화(k-Means clustering)가 가장 널리 쓰입니다.
압축 (Compression / Dimensionality Reduction): "복잡한 데이터 단순화"
머신러닝에서는 보통 '차원 축소'라고 부르는 개념입니다.
- 정의: 수많은 변수(차원)를 가진 복잡한 데이터를 핵심적인 특징만 골라내어 더 낮은 차원으로 줄이는 작업입니다.
- 이미지 설명:
- 오른쪽의 'Swiss Roll in 3D'는 돌돌 말려 있는 입체적인 형태입니다.
- 이를 'Locally Linear Embedding(LLE)'이라는 기술을 통해 평면(2D)으로 쫙 펼친 결과가 옆의 그래프입니다.
- 왜 하나요?
- 데이터 용량을 줄여 계산 속도를 높입니다.
- 너무 복잡해서 눈에 보이지 않는 데이터를 시각화하여 분석하기 쉽게 만듭니다.
- 중요하지 않은 잡음(Noise)을 제거하는 효과가 있습니다.
비지도 학습은 데이터의 정답을 맞히는 것이 아니라, 데이터 자체의 '모양'을 보고 다음과 같은 일을 합니다.
- 군집화: "이 데이터들은 서로 비슷하게 생겼으니 같은 팀이야!"
- 압축: "이 데이터는 너무 복잡하니 핵심만 추려서 간단하게 보여줄게!"
지도 학습 vs 비지도 학습 비교
지도 학습에서 정답을 다는 과정(Labeling)이 매우 비용이 많이 들고 힘들었던 것 기억하시나요? 비지도 학습은 정답이 필요 없기 때문에, 방대한 양의 데이터를 그대로 활용할 수 있다는 강력한 장점이 있습니다.
| 구분 | 지도 학습 (Supervised) | 비지도 학습 (Unsupervised) |
| 데이터 | 정답이 있음 (Labeled) | 정답이 없음 (Unlabeled) |
| 목표 | 정답 맞히기 (분류/회귀) | 숨은 구조 찾기 (군집화) |
| 비용 | 정답 생성 비용 높음 | 상대적으로 낮음 |
그럼 무조건 비지도 학습이 좋냐? 그건아님
1. 목적의 차이: "정답"이 필요한 순간
비지도 학습은 데이터의 '숨겨진 구조'를 찾는 데 목적이 있지만, 우리가 인공지능을 사용할 때는 '명확한 결론'이 필요할 때가 훨씬 많습니다.
- 지도 학습 (정답 필요): "이 사진이 암세포인가요, 정상세포인가요?" → 생명과 직결된 문제에서는 정확한 분류가 필수입니다.
- 비지도 학습 (구조 탐색): "비슷한 사진끼리 묶어봐." → 컴퓨터가 암세포와 정상을 묶을 수도 있지만, 단순히 '색깔이 비슷한 것'끼리 묶어버릴 수도 있습니다. 즉, 사람이 원하는 기준대로 결과가 나온다는 보장이 없습니다.
2. 성능 평가의 어려움
- 지도 학습: 시험 문제와 정답이 있으므로 "정확도 95%"처럼 객관적인 성적(stats)을 낼 수 있습니다.
- 비지도 학습: 정답이 없기 때문에 이 모델이 '정말 잘하고 있는 건지' 판단하기가 매우 주관적입니다. 묶인 결과(Clustered data)를 보고 결국 사람이 다시 해석해야 하는 번거로움이 있습니다.
- 비지도 학습으로 시작: 엄청나게 많은 데이터(Unlabeled)를 컴퓨터에게 주고 스스로 언어의 규칙이나 패턴을 파악하게 합니다. (예: ChatGPT의 기본 학습 단계)
- 지도 학습으로 마무리: 그 후 아주 소량의 고퀄리티 정답 데이터(Labeled)를 주어 사람이 원하는 방식대로 대답하도록 정교하게 다듬습니다.
3. 준지도학습

- 정답 데이터(Labeled data): 사람이 일일이 작업해야 하므로 구하기가 매우 어렵고 비용이 많이 듭니다(Expensive).
- 정답 없는 데이터(Unlabeled data): 인터넷 등에서 널려 있어 구하기가 매우 쉽습니다.
준지도 학습은 이 두 데이터의 장점을 합쳐서 "비용은 줄이면서 성능은 높이려는" 하이브리드 방식
학습 과정: 가짜 정답(Pseudo-label) 만들기
- 소수 정예 학습: 우선 정답이 있는 소수의 데이터(small labeled set)만 가지고 모델을 먼저 학습시킵니다.
- 예측 및 라벨 생성: 학습된 모델을 정답이 없는 대량의 데이터(large unlabeled set)에 적용합니다. 모델은 자신이 배운 대로 이 데이터들의 정답을 예측합니다.
- 의사 라벨링(Pseudo-labeling): 모델이 예측한 값을 '일단 정답이라고 가정'하고 데이터에 붙입니다. 이를 Pseudo-labeled data(가짜 정답 데이터)라고 부릅니다.
- 최종 재학습: 이제 '진짜 정답 데이터'와 모델이 만든 '가짜 정답 데이터'를 모두 합쳐서 모델을 다시 크게 학습시킵니다.
4.강화학습
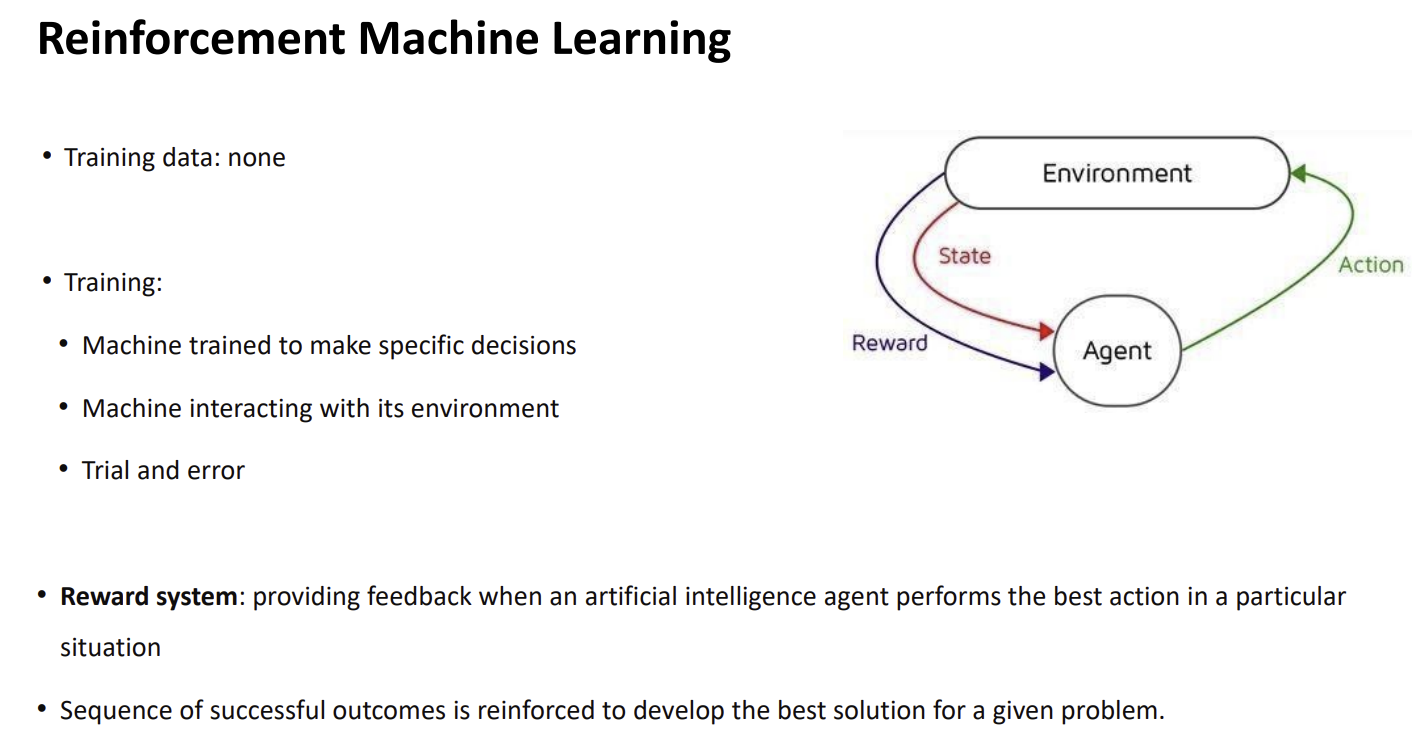
데이터를 주는 대신 '보상(Reward)'을 통해 스스로 최적의 행동을 학습하게 하는 방식입니다.
- 작동 원리: 인공지능 에이전트(Agent)가 환경(Environment)과 상호작용하며 특정 행동(Action)을 하고, 그 결과에 따라 상태(State) 변화와 보상을 받습니다.
- 핵심 키워드: 시행착오(Trial and error)를 거치며 보상을 최대화하는 방향으로 전략을 세웁니다.
- 예시: 알파고와 같은 게임 AI나 자율주행 자동차의 경로 최적화 등에 사용됩니다.
'AI > Machine Learning' 카테고리의 다른 글
| 평가지표와 통계적 판단 (0) | 2025.06.22 |
|---|---|
| 전처리와 분석 (0) | 2025.06.21 |
| 경사하강법 (최적화) (0) | 2025.06.20 |
| 지도학습 Ⅱ (분류) (0) | 2025.06.19 |
| 지도학습 Ⅰ (회귀) (0) | 2025.06.19 |