[LLM 컨셉] Pre-training: 수조 개의 토큰으로 쌓아 올린 지식의 탑
**사전 학습(Pre-training)**은 아무것도 모르는 상태의 모델 가중치를 수천 대의 GPU와 수조 개의 텍스트 데이터를 투입하여 업데이트하는 과정입니다. 이 단계를 거친 모델을 우리는 **'베이스 모델(Base Model)'**이라고 부르며, 비유하자면 세상의 모든 책을 읽었지만 아직 대화하는 법은 배우지 않은 '백과사전형 천재'와 같습니다.
1. 어떻게 스스로 공부하는가? (Self-Supervised Learning)
사전 학습의 가장 큰 특징은 사람이 일일이 정답을 달아줄 필요가 없다는 것입니다. 모델은 텍스트 그 자체를 정답으로 삼아 스스로 학습합니다.
- 인과적 언어 모델링 (Causal Language Modeling): GPT 계열이 사용하는 방식입니다. 앞선 단어들을 보고 **'다음에 올 단어'**를 맞히는 연습을 반복합니다.
- 예: "오늘 날씨가 너무 [ ? ]" → [ ? ]에 들어갈 단어로 '좋다', '흐리다' 등을 예측.
- 마스크 언어 모델링 (Masked Language Modeling): BERT 계열이 사용합니다. 문장 중간에 구멍(Mask)을 뚫어놓고 문맥을 살펴 그 안에 들어갈 단어를 맞힙니다.
- 예: "서울은 대한민국의 [MASK]이다."
2. 무엇을 먹고 자라는가? (Data Pipeline)
거대 모델의 지능은 학습 데이터의 질과 양에 결정됩니다. 단순히 인터넷 글을 다 긁어오는 것이 아니라 정교한 전처리 과정이 필요합니다.
- 데이터 수집 (Collection): Common Crawl(웹 페이지), 위키피디아, 논문, 책, GitHub 코드 등 방대한 데이터를 수집합니다.
- 필터링 (Filtering): 저품질 텍스트, 광고성 글, 중복 데이터, 유해 콘텐츠를 제거합니다. (데이터의 양보다 질이 성능에 더 큰 영향을 미칩니다.)
- 토큰화 (Tokenization): 앞서 배운 토크나이저를 통해 텍스트를 숫자로 변환합니다.
3. 사전 학습의 결과: 베이스 모델 (Base Model)
이 기나긴 학습이 끝나면 탄생하는 것이 베이스 모델입니다. 베이스 모델의 특징은 다음과 같습니다.
- 문장 완성 능력: 질문에 답하기보다는 문장을 이어서 쓰려고 합니다.
- 질문: "대한민국의 수도는 어디야?"
- 베이스 모델의 반응: "대한민국의 수도는 어디야? 라는 질문은 지리 시험에서 자주 출제됩니다. 다음은 수도 목록입니다..." (답변이 아닌 문장 나열)
- 방대한 지식: 세상의 일반적인 상식, 문법, 코딩 규칙 등을 내재화하고 있습니다.
- 창발적 능력: Scaling Law에 따라 일정 규모를 넘어서면 추론 능력이 나타나기 시작합니다.
4. 사전 학습의 엄청난 비용 (Compute & Cost)
사전 학습은 아무나 할 수 없는 '자본의 영역'입니다.
- 연산량: 수천 장의 H100 GPU가 수개월 동안 24시간 풀가동되어야 합니다.
- 비용: 최신 모델(Llama 3, GPT-4 등)의 경우 사전 학습 비용만 수백억 원에서 수천억 원에 달합니다.
- 에너지: 이 과정에서 발생하는 전력 소비와 탄소 배출 문제도 최근 주요 이슈 중 하나입니다.
5. [선생님의 심화 보충] 사전 학습과 지식의 유통기한
사전 학습은 모델의 가중치에 지식을 고정하는 작업입니다. 따라서 학습 데이터가 수집된 시점 이후의 정보는 모델이 알지 못합니다. 이를 **'지식 컷오프(Knowledge Cutoff)'**라고 합니다. 이 한계를 극복하기 위해 나중에 실시간 정보를 찾아보는 RAG(검색 증강 생성) 기술이 등장하게 된 것입니다.
✍️ 공부를 마치며
사전 학습은 LLM이라는 거대한 빙산의 아랫부분과 같습니다. 겉으로 드러나는 대화 능력은 작아 보이지만, 그 밑바닥에는 수조 개의 토큰으로 쌓아 올린 거대한 지식의 층이 존재합니다. 이제 이 백과사전 같은 모델에게 '대화하는 법'을 가르칠 차례입니다.



1. 지식 차단(Knowledge Cutoff)의 문제
LLM은 학습된 시점 이후의 정보는 알지 못하는 근본적인 한계가 있습니다.
- 학습 데이터의 시점: 최신 모델들도 특정 시점까지의 데이터로만 학습됩니다. 예를 들어 GPT-4o는 2023년 10월, Llama 3는 2023년 12월이 지식 차단 시점입니다.
- 최신 정보 부재: 모델은 최신 지식이 필요한 질문에 대해 과거의 데이터를 바탕으로 답변하거나, 잘못된 답변을 내놓는 어려움을 겪습니다. 예시로 2022년 한국 대통령을 묻는 질문에 2023년에 제작된 모델이 정확히 답변하지 못하는 케이스가 제시되어 있습니다.
2. 미세 조정(Fine-tuning)을 통한 지식 습득의 한계
새로운 지식을 주입하기 위해 미세 조정을 시도할 때 발생하는 기술적 제약입니다.
- 성능 저하의 위험: 새로운 지식을 학습시키기 위해 데이터를 피팅(Fitting)하는 과정이 오히려 모델의 전반적인 정확도를 떨어뜨릴 수 있습니다.
- 그래프 분석 (Fitting on new knowledge):
- 과적합(Overfitting): 학습 에포크(Epochs)가 10회를 넘어가면서 이미 알고 있는 지식(Train Known)에 과하게 집착하게 됩니다.
- 검증 정확도(Dev Accuracy) 하락: 과적합이 시작되는 지점부터 실제 성능 지표인 Dev Accuracy가 급격히 하락하는 것을 볼 수 있습니다. 이는 모델이 새로운 지식을 효과적으로 통합하기보다는 단순히 데이터를 암기하려다 범용적인 능력을 잃게 됨을 시사합니다.
이미지 요약 인사이트: 이 자료는 LLM이 **"단순한 학습(Fine-tuning)만으로는 최신 지식을 완벽하게 흡수하기 어렵다"**는 점을 강조합니다. 모델이 기존에 가진 지식과 새로운 정보 사이에서 충돌을 일으키거나 성능이 무너질 수 있기 때문에, 최신 정보를 제공하기 위해서는 디코딩 전략이나 RAG(검색 증강 생성)와 같은 다른 접근 방식이 필요하다는 논리적 근거를 제시합니다.


마지막으로 제공해주신 이미지(image_9f85a1.png)는 거대언어모델(LLM)의 지식 한계를 극복하기 위한 핵심 대안인 **검색 증강 생성(Retrieval-Augmented Generation, RAG)**의 개념과 구조를 다루고 있습니다. 이 이미지의 핵심 내용을 정리해 드립니다.
검색 증강 생성 (Retrieval-Augmentation)
이미지에서는 외부 지식을 검색하고 이를 모델의 입력에 통합하는 것이 LLM의 지식 한계를 해결하는 유망한 방법임을 강조합니다.
1. 핵심 개념 (Key Idea)
- 지식 확장: 새로운 지식을 LLM의 추가적인 입력(Additional Input)으로 제공하여 지식 범위를 확장합니다.
- 표준적 접근: 현재 **RAG(Retrieval-Augmented Generation)**는 LLM의 답변 품질을 높이기 위한 표준적인 접근 방식이 되었습니다.
- Retrieve-and-read: 질문 답변(QA) 시스템을 개선하기 위해 널리 사용되는 대중적인 방식입니다.
2. 시스템 구조 분석 (Illustration for ODQA)
이미지 왼쪽의 아키텍처 다이어그램을 통해 RAG의 작동 단계를 확인할 수 있습니다.
- Question (질문): 사용자가 질문을 입력합니다.
- Retriever (검색기): BM25나 밀집 벡터(dense vector) 검색 기법을 사용하여 외부 지식(External Knowledge) 데이터베이스에서 질문과 관련된 문맥(Related context)을 찾아냅니다.
- Generator (생성기): 검색된 문맥들을 순위화(Ranked contexts)하여 질문과 함께 생성기(BERT, GPT 등)에 전달합니다.
- Answer (답변): 모델은 제공된 외부 지식을 바탕으로 최종 답변을 생성합니다.
3. 실제 적용 예시 (RAG with GPT-4o)
이미지 오른쪽 하단은 실제 서비스에서 RAG가 어떻게 작동하는지 보여줍니다.
- 사용자의 최신 뉴스 관련 질문에 대해, 모델이 실시간으로 외부 사이트를 검색하여 최신 정보를 바탕으로 정확한 답변을 내놓는 과정을 예시로 제시합니다.
이미지 요약 인사이트: 이 자료의 결론은 **"모델을 새로 학습(Fine-tuning)시키지 않아도, 검색을 통해 외부 지식을 수시로 공급해줌으로써 지식 차단 문제를 해결할 수 있다"**는 것입니다. 이는 특히 사실 관계의 정확성이 중요한 정보 검색이나 최신 소식을 다루는 서비스에서 필수적인 기술임을 보여줍니다.

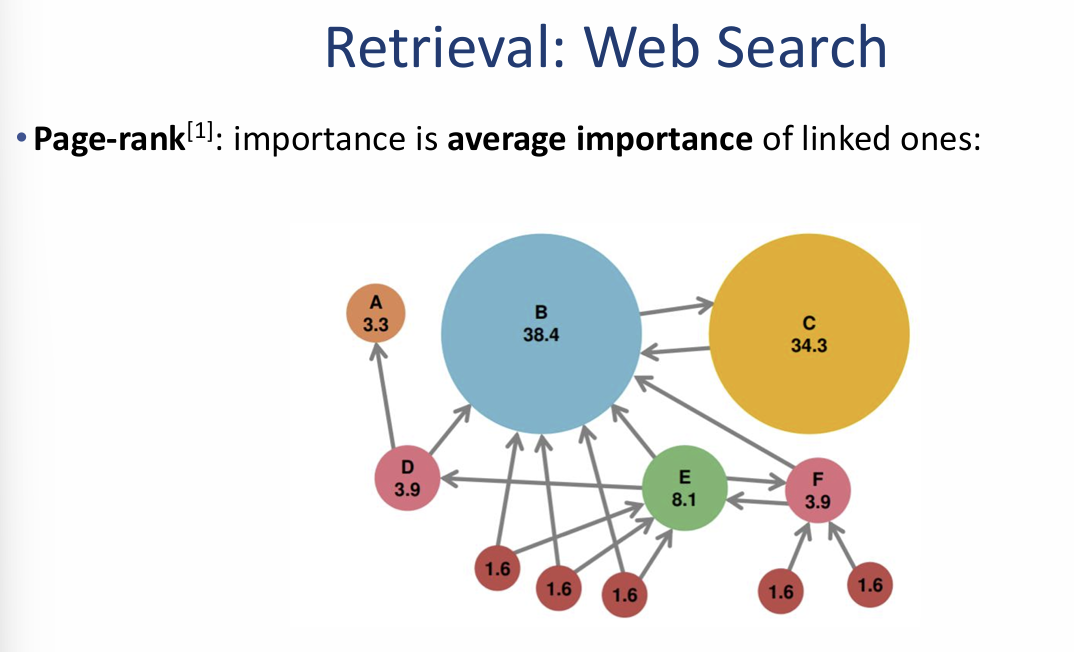
마지막으로 제공해주신 이미지(image_9f89fb.png)는 외부 지식을 가져오는 **검색(Retrieval)**의 대표적인 사례와 웹 페이지의 중요도를 산출하는 페이지 랭크(PageRank) 알고리즘을 다루고 있습니다. 이미지의 핵심 내용을 정리해 드립니다.
1. 검색(Retrieval)의 대표 사례: 웹 검색
- 핵심 도구: 구글 검색(Google Search)과 같은 웹 검색 엔진이 가장 대표적인 검색 시스템입니다.
- 역할: 방대한 인터넷 데이터 중에서 사용자의 질문에 가장 적합한 정보를 찾아내는 검색(Retrieval) 기능을 수행합니다.
2. 검색 엔진의 핵심 원리: 페이지 랭크(Page Rank)
이미지 우측은 구글의 초기 성장을 이끌었던 페이지 랭크 알고리즘의 개념을 시각화하여 보여줍니다.
- 정의: 웹 페이지의 **중요도(Importance)**를 결정하는 알고리즘입니다.
- 산출 방식: 특정 페이지의 중요도는 해당 페이지를 링크(Linked)하고 있는 다른 페이지들의 평균 중요도를 바탕으로 계산됩니다.
-
- 시각적 분석:
- 노드(원)의 크기: 페이지의 중요도를 나타냅니다. 그림에서 B(38.4)와 C(34.3)는 많은 링크를 받고 있어 중요도가 매우 높게 측정됩니다.
- 화살표(링크): 다른 페이지로 연결되는 링크를 의미합니다. 중요도가 높은 페이지(B, C)로부터 링크를 받는 페이지는 자연스럽게 더 높은 점수를 얻게 됩니다.
- 전파 원리: 하단의 작은 페이지들(1.6)이 상위 페이지(E, D)를 가리키고, 다시 이들이 핵심 페이지(B)를 가리키며 중요도가 전달되는 구조를 확인할 수 있습니다.
-
이미지 요약 인사이트: 이 자료는 앞서 살펴본 RAG(검색 증강 생성) 시스템에서 '어떤 문맥(Context)을 가져올 것인가'를 결정할 때, 단순히 키워드만 맞추는 것이 아니라 **웹상의 연결 고리를 통해 검증된 신뢰도 높은 정보(PageRank)**를 우선순위로 두는 것이 검색 품질의 핵심임을 시사합니다.


1. Retrieval: Web Search (PageRank 알고리즘)
웹 페이지의 중요도를 링크 구조를 통해 수학적으로 산출하는 방식입니다.
- 수학적 정의: 페이지 $A$의 중요도 $PR(A)$는 그 페이지로 연결된 다른 페이지들의 중요도를 해당 페이지들이 가진 링크 수($L$)로 나눈 값들의 합으로 결정됩니다.
- 공식: $PR(A) = \frac{1-d}{N} + d \left( \frac{PR(B)}{L(B)} + \frac{PR(C)}{L(C)} + \dots \right)$
- 댐핑 팩터(Damping factor, $d$): 사용자가 링크를 클릭하지 않고 무작위 페이지로 점프할 확률을 의미하며, 보통 $1-d$로 표현됩니다.
- 의미: 수학적으로 $PR(A)$는 사용자가 웹서핑을 무한히 반복했을 때 특정 페이지 $A$에 도달하게 될 확률을 나타냅니다.
- 계산 방식: 초기값($\frac{1}{N}$)에서 시작하여 반복적인 반복법(Iterative method)을 통해 최종 점수를 찾아냅니다.
2. Text-base Retrieval (BM25 알고리즘)
문서 내 단어의 빈도와 희귀성을 바탕으로 질문(Query)과의 유사도를 계산하는 텍스트 레벨 검색의 표준 기법입니다.
- 핵심 원리: 질문에 포함된 키워드가 문서에 많이 나타날수록($word overlap \uparrow$), 검색 순위가 높아집니다($retrieval \uparrow$).
- BM25 스코어 계산:
- IDF(Inverse Document Frequency): 특정 키워드가 전체 문서군에서 얼마나 희귀한지를 측정합니다. 흔한 단어보다 희귀한 단어가 포함된 문서에 더 높은 가중치를 줍니다.
- 문서 길이 보정: 문서의 길이($|D|$)와 평균 문서 길이($avgdl$)를 고려하여, 단순히 길다는 이유로 점수가 높아지는 것을 방지합니다.
- 포화 효과: 특정 단어가 과도하게 반복될 때 점수가 무한정 높아지지 않도록 $k_1, b$와 같은 하이퍼파라미터를 사용하여 조절합니다.
이미지 요약 인사이트:
이 자료는 현대적인 검색 시스템이 **링크 구조를 통한 권위도(PageRank)**와 **텍스트 내용의 일치도(BM25)**라는 두 가지 축을 어떻게 수학적으로 결합하여 사용자에게 최적의 정보를 제공하는지 보여줍니다.


1. Dense Passage Retrieval (DPR)
DPR은 두 개의 독립적인 인코더(예: BERT)를 사용하여 질문과 문서 사이의 유사도를 계산하는 방식입니다.
- 유사도 계산: 질문($q$)과 지문($p$)의 특징 벡터를 추출한 후, 두 벡터의 내적(Dot-product) 값을 통해 유사도를 측정합니다.
- $sim(q, p) = E_Q(q)^\top E_P(p)$
- 학습 방식: 대조 학습(Contrastive loss)을 사용합니다.
- 정답($p^+$): 레이블이 지정된 실제 정답 데이터입니다.
- 오답($p^-$): 어려운 오답(difficulty) 및 배치 내 다른 데이터(in-batch negatives)를 활용하여 모델이 정답을 더 잘 구별하도록 학습시킵니다.
2. Contriever (Self-supervised Dense Retrieval)
Contriever는 사람이 직접 레이블을 단 데이터 없이도 스스로 학습할 수 있는 자기 지도 학습(Self-supervised training) 방식입니다.
- 핵심 아이디어: 사람이 만든 정답 대신, 인공적으로 생성된 데이터를 정답으로 간주하여 학습합니다.
- 데이터 구성:
- 양성 문서($k_+$): 동일한 문서 내에서 무작위로 추출(Crop)한 텍스트 조각을 정답으로 봅니다.
- 음성 문서($k_i$): 아예 다른 문서에서 가져온 텍스트를 오답으로 봅니다.
- 학습 수식: InfoNCE 손실 함수와 유사한 형태의 대조 손실을 사용하여, 인공적으로 생성된 정답 쌍의 유사도는 높이고 오답 쌍의 유사도는 낮추도록 모델을 최적화합니다.
이미지 요약 및 인사이트:
이 자료는 BM25와 같은 단순 단어 매칭 기반의 '희소 검색(Sparse Retrieval)'을 넘어, 문맥의 의미를 파악하는 **밀집 검색(Dense Retrieval)**이 어떻게 발전해왔는지를 보여줍니다.

Retrieval 기법별 성능 비교 및 분석
이미지에서는 "아직 어떤 검색 방법이 최고인지에 대한 단 하나의 정답은 없다"는 점을 강조하며, 데이터셋과 모델에 따른 성능 차이를 보여줍니다.
1. 핵심 인사이트
- 테스트 분포의 중요성: DPR이나 Contriever 같은 모델들은 특정 데이터를 기반으로 학습(Training-based)되기 때문에, 실제 사용 시의 **테스트 데이터 분포(Test distribution)**가 학습 때와 얼마나 유사한지가 성공의 핵심 요소입니다.
- 상황별 최적 모델 상이: 표를 보면 데이터셋(NQ, WebQ, 2Wiki 등)에 따라 성능이 가장 좋은 검색 기법이 계속해서 달라지는 것을 확인할 수 있습니다.
2. 성능 데이터 분석 (Effectiveness for RAG with SuRe)
ChatGPT, GPT-4, LLaMA2-chat 모델을 대상으로 BM25, DPR, Contriever 등의 성능을 비교했습니다.
- 전통적 방식의 건재 (BM25):
- 2Wiki 데이터셋에서 ChatGPT 기준 BM25는 27.4를 기록하여 DPR(19.2)보다 높은 성능을 보였습니다.
- 키워드 매칭 기반인 BM25가 특정 상황에서는 딥러닝 기반 모델보다 더 효과적일 수 있음을 시사합니다.
- 밀집 검색의 강점 (DPR & Contriever):
- NQ 데이터셋에서는 DPR(36.1)과 Contriever(35.8)가 BM25(28.4)를 크게 앞질렀습니다.
- SuRe 기법과의 결합: 모든 검색 방법론에서 'SuRe'라는 추가 기법을 결합했을 때 성능이 일관되게 향상되는 결과(평균 점수 상승)를 보여줍니다.
- 예: Contriever 단독(29.4) → Contriever + SuRe(33.8).
이미지 요약 인사이트: 이 자료는 **"만능 검색 알고리즘은 없다"**는 실무적인 교훈을 줍니다. 사용자는 자신이 해결하려는 도메인의 데이터 특성에 맞춰 **BM25(키워드 중심)**와 DPR/Contriever(의미 중심) 중 무엇이 더 적합한지 실험을 통해 결정해야 하며, SuRe와 같은 보정 기법을 활용해 시너지를 낼 수 있음을 보여줍니다.
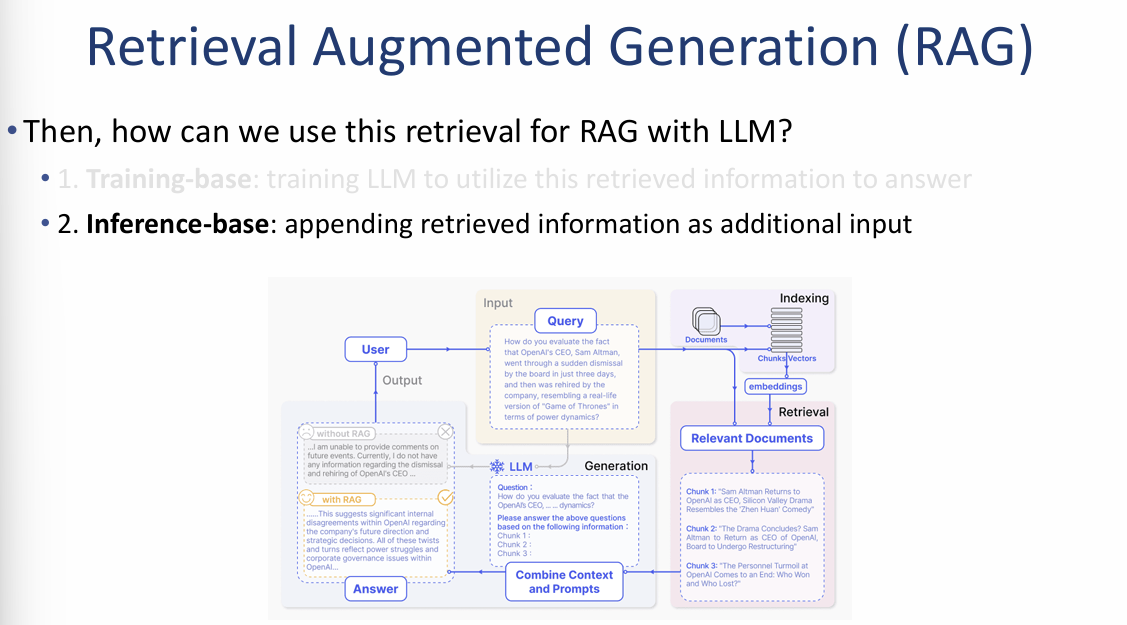
Retrieval Augmented Generation (RAG)의 활용 방식
검색된 정보를 LLM에 어떻게 적용할 것인가에 대해 두 가지 접근법이 있지만, 이미지에서는 현재 가장 널리 쓰이는 추론 기반(Inference-base) 방식을 중점적으로 설명합니다.
1. 추론 기반 방식 (Inference-base)
- 핵심 원리: LLM을 새로 학습시키지 않고, 검색된 정보를 질문과 함께 **추가적인 입력(Additional Input)**으로 덧붙여 제공하는 방식입니다.
- 작동 메커니즘: 검색된 문맥(Context)을 프롬프트에 포함시켜 LLM에게 "제공된 정보를 바탕으로 답변하라"고 지시합니다.
2. 전체 시스템 워크플로우 (Architecture)
중앙의 다이어그램을 통해 질문 입력부터 최종 답변 생성까지의 5단계 과정을 확인할 수 있습니다.
- Indexing (색인): 방대한 문서 데이터를 조각(Chunks)으로 나누고, 임베딩 모델을 통해 벡터(Vectors)로 변환하여 저장합니다.
- Query (질문): 사용자의 질문이 입력되면 시스템은 이를 이해하고 검색을 준비합니다.
- Retrieval (검색): 질문과 가장 관련 있는 문서 조각(Relevant Documents)들을 데이터베이스에서 찾아냅니다.
- Combine & Generation (결합 및 생성): 질문과 검색된 문서 조각들을 하나로 결합하여 LLM에게 전달합니다.
- 프롬프트 예시: "다음 정보를 바탕으로 위 질문에 답변하세요: Chunk 1, Chunk 2..."
- Answer (답변): LLM은 제공된 문맥을 참고하여 환각을 최소화한 정확한 답변을 생성합니다.
이미지 요약 및 인사이트: 이 자료는 RAG의 가장 큰 장점인 **"지식의 즉시 업데이트 가능성"**을 보여줍니다. 모델을 재학습시키는 번거로운 과정 없이도, 외부 지식을 프롬프트에 동적으로 추가(Appending)함으로써 최신 정보를 정확하게 전달할 수 있는 시스템적 구조를 명확히 제시하고 있습니다.

REPLUG (REtrieval and PLUG)
REPLUG는 타겟 언어 모델의 내부 파라미터를 수정할 수 없는 상황에서도 검색 성능을 개선할 수 있도록 설계된 프레임워크입니다.
1. 기본 가정 (Assumption)
- Black-box 모델: 타겟 언어 모델(Reader)은 파라미터에 접근하거나 이를 업데이트할 수 없는 '블랙박스' 상태라고 가정합니다 (예: API로만 제공되는 GPT-4 등).
2. 핵심 아이디어 (Key Idea)
- 입력부 결합 (Prepending): 기존의 검색 기법(예: Contriever)으로 문서를 찾은 뒤, 이를 입력값의 앞부분에 간단히 덧붙여서(Prepending) 모델에 전달합니다.
- 블랙박스 모델을 이용한 미세 조정: 타겟 모델의 내부를 건드리지 않고도 검색기(Retriever)의 성능을 더욱 향상시키기 위해, 블랙박스 모델의 피드백을 활용하여 검색기를 미세 조정하는 새로운 방식을 제안합니다.
3. 기존 방식 vs REPLUG 비교
| 구분 | Previous (기존 방식) | RE-PLUG |
| 타겟 LM 상태 | 내부 파라미터 수정이 가능한 White-box 모델 (보통 10B 이하 소형 모델) | 파라미터가 고정(Frozen)된 Black-box 모델 (100B 이상의 거대 모델) |
| 검색기(Retriever) | 고정된(Frozen) 검색기 사용 | 블랙박스 모델의 신호를 바탕으로 학습 가능(Trainable) |
| 작동 원리 | 고정된 검색 결과가 화이트박스 모델로 전달됨 | 블랙박스 모델이 주는 피드백을 통해 검색기 자체를 최적화하여 더 나은 결과 도출 |
이미지 요약 및 인사이트:
이 자료의 핵심은 **"모델의 내부를 고칠 수 없다면, 모델에게 주는 입력 정보(검색 결과)를 모델 입맛에 맞게 최적화하자"**는 전략입니다. REPLUG는 거대 모델이 어떤 정보를 더 선호하는지 파악하여 검색기를 학습시킴으로써, 폐쇄적인 API 기반 모델 환경에서도 RAG 성능을 극대화할 수 있는 영리한 해결책을 제시합니다.
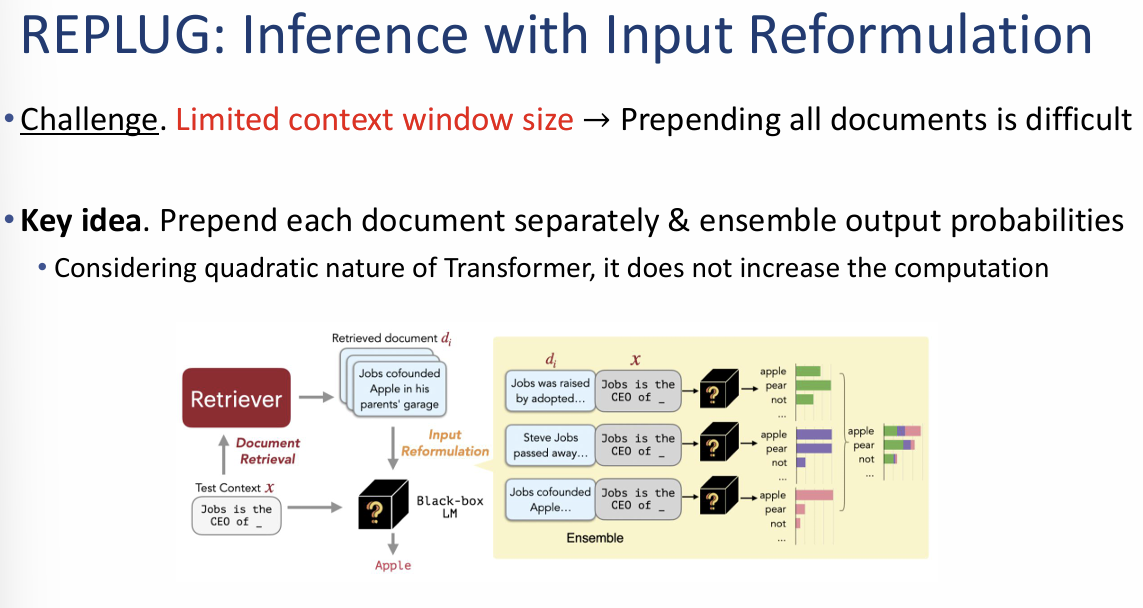
REPLUG: Inference with Input Reformulation
이 단계에서는 검색된 여러 문서를 제한된 모델의 입력창(Context window)에 어떻게 효율적으로 넣고 처리할 것인가에 대한 해결책을 제시합니다.
1. 도전 과제 (Challenge)
- 제한된 컨텍스트 창: 언어 모델이 한 번에 읽을 수 있는 토큰의 양은 한정되어 있습니다.
- 문서 결합의 어려움: 검색된 수많은 문서를 단순히 모두 앞부분에 덧붙여서(Prepending) 모델에 넣는 것은 물리적으로 불가능하거나 매우 어렵습니다.
2. 핵심 아이디어: 개별 결합 및 앙상블 (Ensemble)
모든 문서를 한 번에 넣는 대신, 문서를 하나씩 따로 처리하여 결과를 합치는 방식을 사용합니다.
- 개별 처리: 검색된 각 문서($d_i$)를 질문($x$)과 개별적으로 결합하여 모델에 입력합니다.
- 예: "Jobs was raised..." + 질문 / "Steve Jobs passed away..." + 질문 등.
- 확률 앙상블 (Ensemble): 각 문서별로 나온 출력 확률 분포(Output probabilities)를 최종적으로 하나로 결합하여 단어를 예측합니다.
- 연산 효율성: 트랜스포머 모델의 연산 특성상, 문서를 길게 하나로 묶어 처리하는 것보다 이렇게 나누어 처리하는 것이 전체 연산량을 크게 증가시키지 않으면서도 효과적입니다.
이미지 요약 및 인사이트:
이 자료의 핵심은 **"나눠서 읽고 합쳐서 결론 내기"**입니다. 모델이 한 번에 읽기 힘든 방대한 양의 검색 결과가 있더라도, 이를 개별 문서 단위로 쪼개어 모델에게 물어보고 그 답변들의 확률을 종합함으로써 모델의 입력 제한 문제를 지능적으로 해결할 수 있음을 보여줍니다.


1. REPLUG: 입력 재구성을 이용한 추론 (Inference)
제한된 컨텍스트 창(Context window) 문제를 해결하기 위해 검색된 각 문서를 독립적으로 처리한 후 결합하는 수학적 방식입니다.
- 확률 결합 수식: 질문 $x$와 검색된 Top-K 문서 집합 $\mathcal{D}'$이 주어졌을 때, 다음 토큰 $y$가 생성될 확률은 다음과 같이 계산됩니다.
- $p(y | d \circ x)$: 개별 문서($d$)와 질문($x$)을 결합했을 때 모델이 예측한 확률입니다.
- $\lambda(d, x)$: 검색 모델이 계산한 질문과 문서 사이의 유사도 점수(가중치)입니다.
-
$$p(y | x, \mathcal{D}') = \sum_{d \in \mathcal{D}'} p(y | d \circ x) \cdot \lambda(d, x)$$
- 유사도 가중치 계산: 소프트맥스(Softmax) 함수와 유사한 공식을 사용하여, 질문과 더 관련 있는 문서의 예측 결과에 더 큰 비중을 둡니다.
2. REPLUG: 밀집 검색기 미세 조정 (Fine-tuning Dense Retriever)
학습 가능한 모듈이 없는 블랙박스 모델의 성능을 끌어올리기 위해 LSR(LM-Supervised signal for fine-tuning Retriever) 기법을 사용합니다.
- 핵심 원리: 검색기(Retriever)가 찾은 문서들의 중요도 분포를 언어 모델(LM)이 실제로 정답을 맞히는 데 기여한 정도와 일치하도록 업데이트합니다.
- 학습 단계:
- 검색기 우도 계산 ($P_r$): 현재 검색기가 각 문서($d_1, d_2, \dots$)에 부여한 확률 분포를 구합니다.
- LM 우도 계산 ($Q$): 언어 모델이 각 문서를 참고했을 때 정답(예: 'apple')을 생성할 확률을 계산하여, 실제 도움이 된 문서의 비중을 파악합니다.
- KL Divergence ($P || Q$): 검색기의 분포($P$)와 언어 모델의 선호도 분포($Q$) 사이의 차이를 줄이도록 검색기를 학습시킵니다.
이미지 요약 및 인사이트:
이 자료는 REPLUG가 단순히 문서를 덧붙이는 수준을 넘어, **"언어 모델이 정답을 내놓는 데 진짜 도움이 된 문서가 무엇인지"**를 역으로 검색기에 가르치는 지능적인 학습 구조를 가지고 있음을 보여줍니다. 이를 통해 파라미터가 고정된 거대 모델을 사용하더라도, 검색 단계를 최적화하여 전체적인 시스템 성능을 개선할 수 있습니다.

REPLUG: 밀집 검색기 미세 조정 (Fine-tuning Dense Retriever)
이 기법의 핵심은 **"언어 모델(LM)이 실제로 정답을 맞히는 데 도움이 된 문서를 검색기도 중요하게 인식하도록 만드는 것"**입니다.
1. 검색 우도 계산 (Computing retrieval likelihood)
현재 검색기가 주어진 질문($x$)에 대해 특정 문서($d$)를 얼마나 중요하다고 판단하는지 확률 분포로 나타냅니다.
- 수식: $P_R(d|x) = \frac{e^{s(d,x)/\gamma}}{\sum_{d \in \mathcal{D}'} e^{s(d,x)/\gamma}}$
- 의미: 검색 모델이 계산한 질문과 문서 사이의 유사도 점수($s$)를 바탕으로 $K$개의 문서에 대한 확률 분포를 구합니다.
2. LM 우도 계산 (Computing LM likelihood)
언어 모델이 실제로 특정 문서($d$)를 참고했을 때 정답($y$)을 얼마나 잘 예측했는지 선호도를 계산합니다.
- 수식: $Q(d|x, y) = \frac{e^{P_{LM}(y|d,x)/\beta}}{\sum_{d \in \mathcal{D}'} e^{P_{LM}(y|d,x)/\beta}}$
- 의미: 블랙박스 언어 모델이 각 문서를 바탕으로 정답($y$)을 낼 확률($P_{LM}$)을 측정합니다. 이 값이 높을수록 해당 문서는 정답을 맞히는 데 **'실질적인 도움'**이 된 문서입니다.
3. 검색기 업데이트 (Update retriever to minimize KL divergence)
검색기의 판단($P_R$)과 언어 모델의 실질적 선호도($Q$) 사이의 간극을 줄입니다.
- 손실 함수: $\mathcal{L} = \frac{1}{|\mathcal{B}|} \sum_{x \in \mathcal{B}} KL(P_R(d|x) || Q_{LM}(d|x, y))$
- 의미: **KL 발산(KL Divergence)**을 최소화함으로써, 검색기가 앞으로는 언어 모델이 좋아할 만한(정답률을 높여주는) 문서를 우선적으로 찾아오도록 학습시킵니다.
이미지 요약 및 인사이트:
이 자료는 REPLUG가 **"언어 모델의 지도를 받는 검색기(LM-Supervised Retriever)"**라는 점을 수학적으로 증명합니다. 블랙박스 모델의 내부는 건드릴 수 없지만, 그 모델이 내뱉는 확률값($Q$)을 '선생님'으로 삼아 검색기를 미세 조정함으로써 시스템 전체의 **일관성(Consistency)**과 성능을 향상시킬 수 있음을 보여줍니다.


REPLUG 실험 결과 및 분석
실험 결과에 따르면, REPLUG는 모델의 크기나 기본 성능에 관계없이 일관되게 언어 모델의 능력을 향상시키는 것으로 나타났습니다.
1. 일반 언어 모델링 성능 (Pile 데이터셋)
이미지 왼쪽의 표는 다양한 크기의 GPT-2 및 GPT-3(Black-box) 모델에 REPLUG를 적용한 결과입니다.
- 성능 향상: 모든 모델에서 기본형(Original)보다 REPLUG를 적용했을 때 성능 지표(BPB)가 개선되었습니다.
- LSR의 효과: 단순히 문서를 덧붙이는 것(+REPLUG)보다, 언어 모델의 신호로 검색기를 미세 조정하는 **LSR 기법(+REPLUG LSR)**을 사용했을 때 성능 이득(Gain %)이 훨씬 컸습니다.
- 예: GPT-2 Small 모델은 일반 REPLUG 시 5.3% 개선되었으나, LSR 적용 시 **9.0%**까지 성능이 크게 향상되었습니다.
2. 상식 추론(MMLU) 및 질의응답(QA) 성능
오른쪽의 표는 지식 집약적인 태스크에서의 성능 비교를 보여줍니다.
- MMLU 결과: Codex, PaLM 등 거대 모델에 REPLUG를 결합하면 기본 성능(All)보다 향상된 결과를 얻을 수 있습니다.
- Codex 모델(68.3)은 REPLUG LSR 적용 시 71.8까지 점수가 상승했습니다.
- QA 결과 (NQ, TQA): 질문 답변 데이터셋에서도 REPLUG LSR은 다른 최신 모델(RETRO, Atlas 등)과 대등하거나 더 우수한 성능을 기록했습니다.
- NQ 데이터셋에서 Codex + REPLUG LSR 조합은 45.5를 기록하여 가장 높은 정확도를 보였습니다.
종합 요약 및 인사이트
이 실험 데이터들은 **"검색 모델을 언어 모델에 맞춰 최적화(LSR)하는 것이 시스템 전체 성능을 결정짓는 핵심"**임을 증명합니다. 특히 파라미터를 수정할 수 없는 거대 블랙박스 모델(GPT-3, Codex 등)을 사용할 때, REPLUG 프레임워크가 실질적인 성능 돌파구가 될 수 있음을 시사합니다.

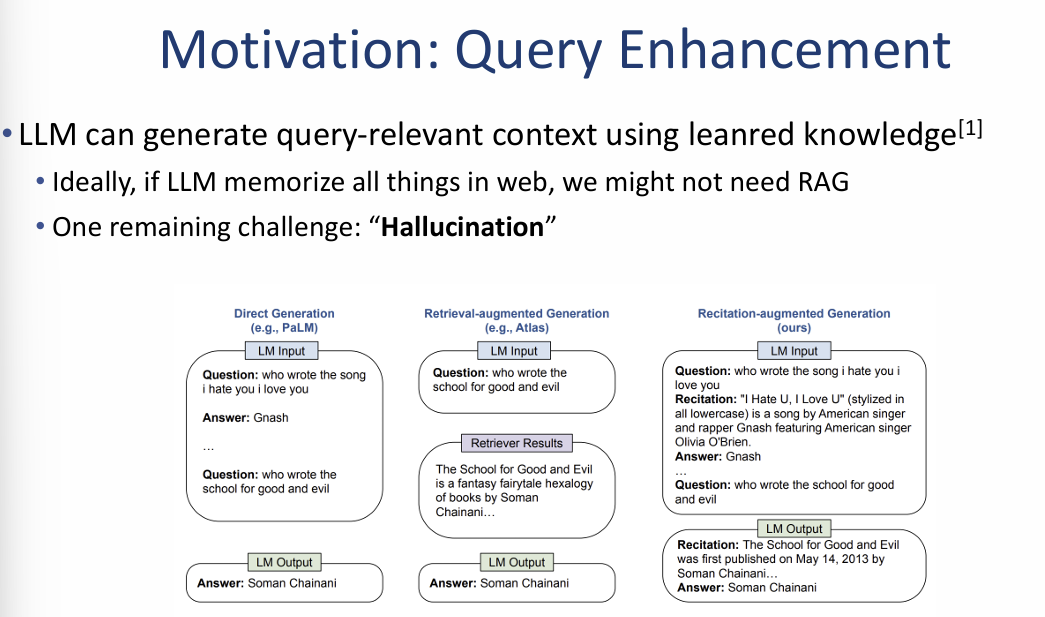
1. 동기: 제로샷 검색(Zero-shot Retrieval)의 필요성
많은 검색 시스템이 성능 향상을 위해 레이블이 지정된 데이터(Relevance labels) 학습에 의존하지만, 실제 환경에서는 이러한 데이터를 구하기 어렵습니다.
- 한계: Contriever와 같은 모델도 충분한 성능을 내려면 레이블 데이터가 필요하며, 이러한 데이터가 없는 경우를 위해 '제로샷 검색' 능력이 필수적입니다.
- 성능 데이터: MKQA 데이터셋 기반의 다국어 검색 실험 결과, 모델별로 언어에 따라 검색 성능(Recall@20, @100)이 크게 차이 남을 보여줍니다.
2. 쿼리 강화: LLM의 내부 지식 활용
LLM은 학습 과정에서 축적된 지식을 바탕으로 질문과 관련된 문맥을 스스로 생성할 수 있습니다.
- 이상적인 시나리오: 만약 LLM이 웹상의 모든 정보를 완벽히 암기하고 있다면 RAG 자체가 필요 없을 수 있습니다.
- 남은 과제: 하지만 모델이 잘못된 정보를 생성하는 할루시네이션(Hallucination) 문제는 여전히 해결해야 할 과제입니다.
3. 생성 방식의 비교 분석 (Architecture Comparison)
이미지 우측 하단은 질문에 답하는 세 가지 서로 다른 아키텍처를 비교합니다.
- 직접 생성 (Direct Generation): 추가 정보 없이 질문만으로 모델이 바로 답변을 생성합니다.
- 검색 증강 생성 (Retrieval-augmented Generation): 외부 검색기(Retriever)가 찾아준 문맥을 참고하여 답변합니다.
- 암기 증강 생성 (Recitation-augmented Generation): 답변을 내놓기 전, 모델이 먼저 질문과 관련된 지식을 스스로 '암기(Recitation)'하여 출력하고, 이를 바탕으로 최종 답변을 생성합니다.
- 예시: "누가 이 노래를 썼나?"라는 질문에 대해, 모델이 먼저 해당 노래의 가사와 정보를 스스로 읊은(Recite) 뒤 "Gnash"라는 정답을 도출합니다.
이미지 요약 및 인사이트: 이 자료는 외부 검색 결과가 부정확하거나 없을 때, LLM이 가진 내부 지식을 먼저 인출(Recitation)하게 함으로써 답변의 정확도를 높이는 전략을 제시합니다. 이는 외부 검색(RAG)과 내부 지식 활용 사이의 균형을 맞추는 새로운 최적화 방향을 보여줍니다.
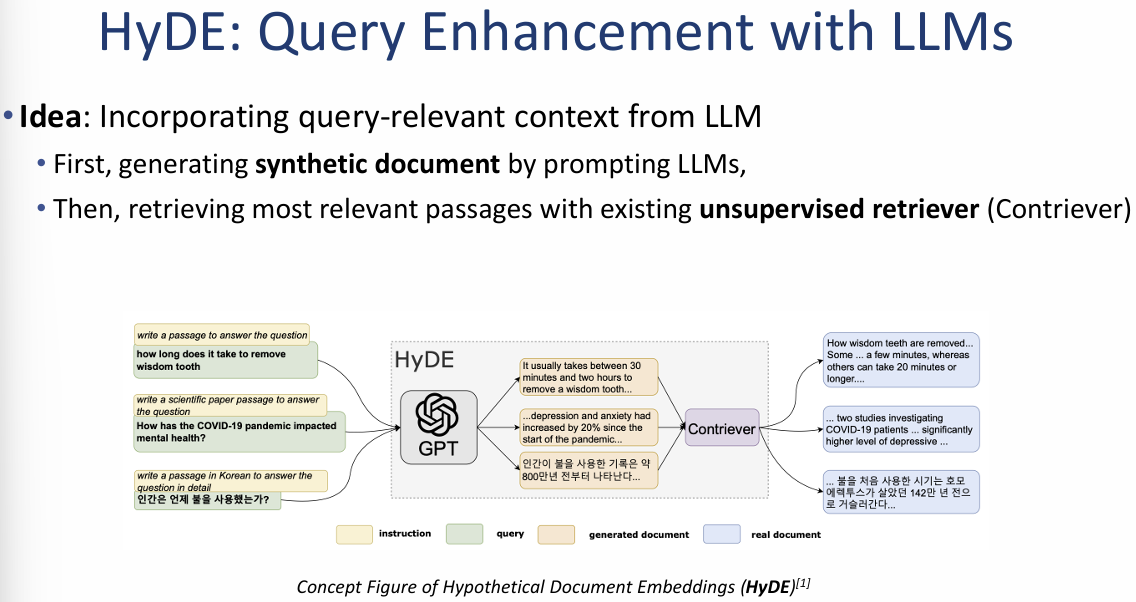

HyDE: Query Enhancement with LLMs
HyDE는 사용자의 질문에서 바로 검색을 수행하는 대신, LLM이 생성한 '가상의 정답 문서'를 활용하여 검색 품질을 높이는 기법입니다.
1. 핵심 아이디어 (Key Idea)
- 가상 문서 생성 (Synthetic Document): 먼저 LLM(예: GPT)에게 질문을 던져, 그에 대한 가상의 정답 문서($\tilde{p}$)를 생성하게 합니다.
- 비지도 검색 (Unsupervised Retrieval): 생성된 가상 문서를 쿼리로 삼아, 학습되지 않은 기존의 검색기(예: Contriever)를 통해 실제 관련 지문들을 찾아냅니다.
- *
2. 작동 원리 및 수식 (Technical Recap)
기존의 밀집 검색(Dense Retrieval) 모델은 질문 인코더($E_Q$)와 지문 인코더($E_P$) 두 가지를 사용하지만, HyDE는 이를 변형합니다.
- 지문 인코더만 사용: 질문 인코더 대신, LLM이 만든 가상 문서($\tilde{p}(q)$)를 지문 인코더($E_P$)에 통과시켜 유사도를 계산합니다.
- 수식: $sim(q, p) = E_P(\tilde{p}(q))^\top E_P(p)$
- 품질 향상 전략: 검색의 정확도를 높이기 위해 하나의 가상 문서만 쓰는 것이 아니라, 여러 개의 가상 문서를 생성하여 그 평균값을 활용할 수 있습니다.
- 수식: $sim(q, p) = (\sum_{k=1}^K E_P(\tilde{p}_k(q))/K)^\top E_P(p)$
이미지 요약 및 인사이트:
HyDE의 핵심은 **"질문보다 정답이 검색하기 더 쉽다"**는 통찰에 있습니다. 질문 자체는 짧고 모호할 수 있지만, LLM이 만든 가상의 정답 문서는 실제 정답 문서와 비슷한 단어와 문맥을 포함할 가능성이 높기 때문에, 이를 검색의 징검다리로 활용하여 검색 성능을 획기적으로 개선합니다.
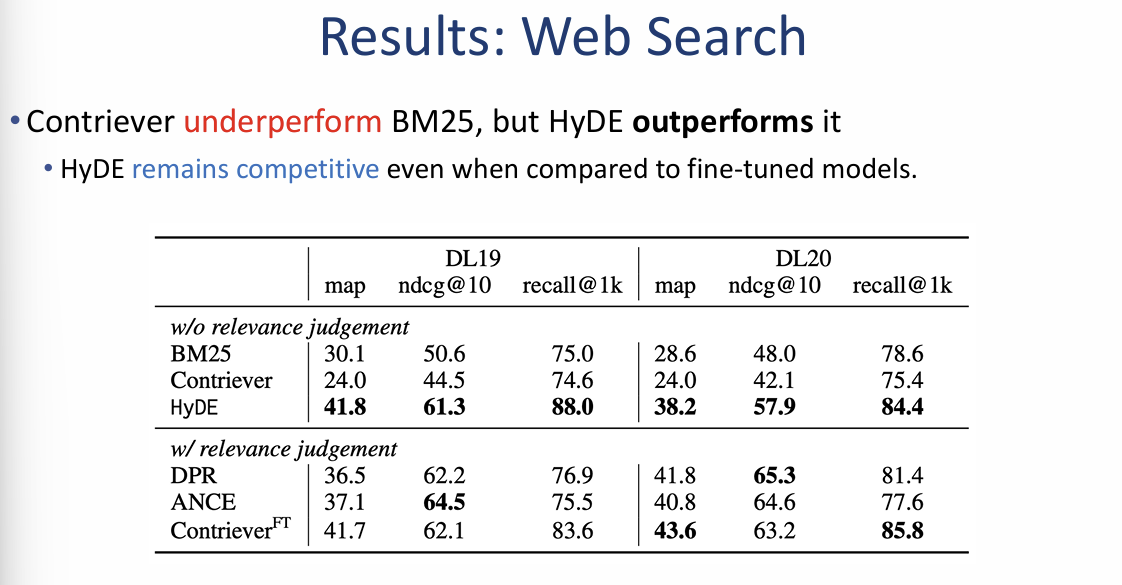
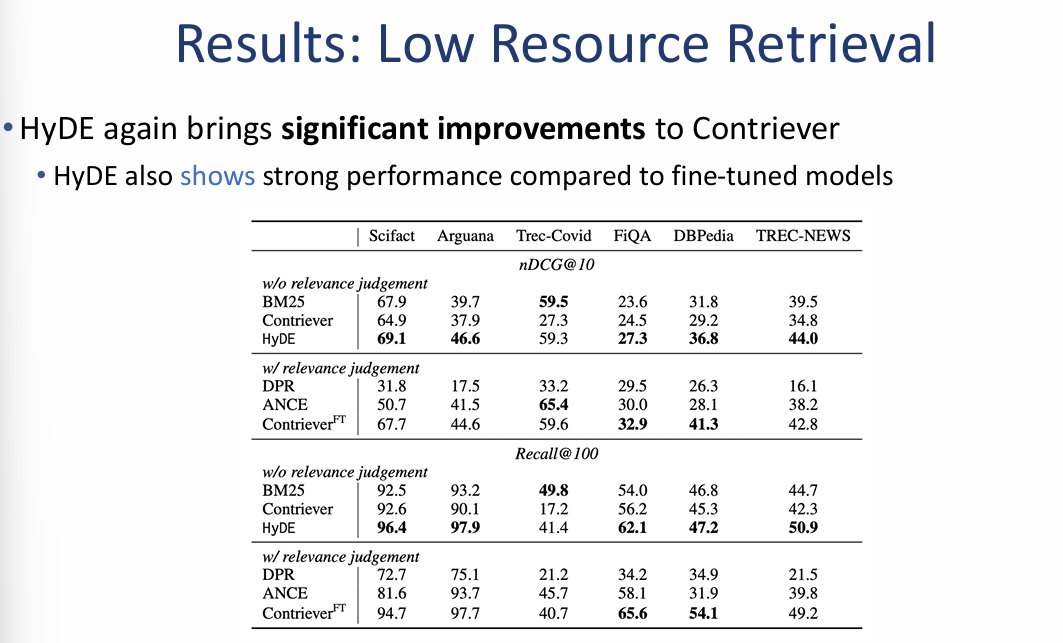
HyDE 성능 분석 및 실험 결과
HyDE는 별도의 관련성 레이블(Relevance labels) 학습 없이도 다양한 도메인에서 매우 강력한 검색 성능을 보여줍니다.
1. 웹 검색 결과 (Web Search Results)
이미지 왼쪽의 표는 DL19 및 DL20 데이터셋에서의 성능 비교입니다.
- BM25 및 Contriever 압도: 정밀도($ndcg@10$)와 재현율($recall@1k$) 모든 지표에서 HyDE는 기본형인 Contriever와 전통적 방식인 BM25를 크게 앞질렀습니다.
- 예: DL19 데이터셋에서 재현율($recall@1k$) 기준 HyDE는 88.0을 기록하여 Contriever(74.6)와 BM25(75.0)보다 높은 성능을 보였습니다.
- 미세 조정 모델과 대등한 성능: 관련성 레이블로 직접 학습된 모델(DPR, ANCE 등)과 비교해도 HyDE는 여전히 경쟁력 있는 성능을 유지합니다.
2. 저자원 검색 결과 (Low Resource Retrieval Results)
오른쪽의 표는 데이터가 부족한 다양한 도메인(Trec-Covid, FiQA, DBPedia 등)에서의 성능을 보여줍니다.
- 일관된 성능 향상: HyDE는 실험에 사용된 거의 모든 데이터셋에서 Contriever에 비해 획기적인 성능 향상을 가져왔습니다.
- 특히 Trec-NEWS 데이터셋에서 $ndcg@10$ 점수가 Contriever의 34.8에서 HyDE의 44.0으로 크게 상승했습니다.
- 강력한 제로샷 성능: 학습 데이터가 없는 상황에서도 HyDE는 미세 조정된 모델(Contriever$^{FT}$)들과 비슷하거나 더 뛰어난 성능을 보이며 제로샷 검색의 효율성을 입증했습니다.


Beyond HyDE: LameR (Large language model as Retriever)
HyDE가 가상의 문서를 생성하여 검색을 돕는다면, LameR은 LLM을 직접 검색 시스템의 핵심 루프로 활용하여 검색과 답변 생성의 선순환 구조를 만듭니다.
1. 핵심 아이디어 (Key Idea)
- 단계적 검색 고도화: 단순한 1회성 검색이 아니라, **[초기 검색 → 초기 답변 생성 → 정밀 검색]**의 과정을 거쳐 검색 결과와 답변의 질을 동시에 높입니다.
- 범용적 적용: 꼭 Contriever 같은 특정 모델을 쓸 필요 없이, BM25와 같은 전통적인 검색 엔진에도 LLM의 초안 작성을 결합하여 성능을 개선할 수 있습니다.
2. LameR 시스템 워크플로우
이미지 왼쪽 하단의 다이어그램을 통해 상세 과정을 확인할 수 있습니다.
- 초기 검색: 질문(Query)을 바탕으로 문서 집합에서 후보군을 리트리브합니다.
- 초안 답변 생성: 검색된 후보들을 바탕으로 LLM이 정제된 답변 초안을 생성합니다.
- 정밀 검색 (Finer Retrieval): 생성된 초안과 원본 질문 사이의 차이점이나 보완할 점을 파악하여, 더 정확하고 구체적인 최종 결과를 도출합니다.
3. 성능 비교 데이터 (TREC Deep Learning 2019/2020)
이미지 오른쪽의 표는 LameR이 기존 기법들을 얼마나 앞서는지 보여줍니다.
- 제로샷 검색 우위: LameR은 학습 데이터가 없는 상황에서도 HyDE나 BM25보다 월등한 성능을 보입니다.
- DL19 데이터셋에서 LameR은 47.2(MAP), **69.1(nDCG@10)**을 기록하여 HyDE(41.8 / 61.3)를 크게 제쳤습니다.
- 미세 조정 모델 압도: 놀랍게도 별도의 미세 조정을 거친 DPR(36.5)이나 Contriever$^{FT}$(41.7)보다도 제로샷 상태의 LameR 성능이 더 높게 나타났습니다.
이미지 요약 인사이트: LameR의 성공은 **"LLM을 단순한 답변 생성기가 아닌, 검색 과정 자체를 지휘하는 리트리버(Retriever)로 활용"**할 때 가장 강력한 시너지가 난다는 점을 시사합니다. 이는 검색 증강 생성(RAG)이 단순히 지식을 '찾아오는' 것을 넘어, 지식을 '어떻게 더 잘 찾아올지'를 LLM 스스로 고민하게 만드는 방향으로 진화하고 있음을 보여줍니다.


Motivation: Noisy-robust RAG
이 자료는 검색된 정보가 항상 정확하지는 않으며, 잘못된 정보(Noisy retrieval)가 포함되었을 때 모델의 성능이 오히려 저하될 수 있음을 지적합니다.
1. 노이즈 검색의 부정적 영향
- 성능 저하: 검색된 내용에 오류가 있거나 질문과 관련이 없는 경우, LLM은 직접 답변할 때보다 더 낮은 성능을 보일 수 있습니다.
- 실패 사례 예시: "제너럴 호스피털에서 제이슨 역을 맡은 배우는 누구인가?"라는 질문에 대해:
- 일반 LLM: "Steve Burton"이라고 정확히 답변합니다.
- RAG 모델: 잘못된 인물 정보가 포함된 텍스트를 검색해와서 "Jason Gerhardt"라고 오답을 내놓는 현상이 발생합니다.
2. 목표: 검색 강건 모델 (Retrieval-robust LLMs)
검색 시스템의 불완전함을 인정하고, 이를 극복하기 위한 LLM의 두 가지 핵심 지향점을 제시합니다.
- 성능 개선: 검색된 문맥이 질문과 관련이 있을 때는 모델의 성능이 확실히 향상되어야 합니다.
- 성능 유지: 검색된 문맥이 질문과 무관하거나 잘못된 정보(Irrelevant)일지라도, 모델의 기본 성능을 해치지 않아야 합니다.
이미지 요약 및 인사이트: 이 자료의 핵심은 **"검색 결과가 독이 되어서는 안 된다"**는 것입니다. RAG 시스템을 구축할 때 단순히 지식을 찾아오는 것에 그치지 않고, 모델이 검색된 정보의 진위나 관련성을 스스로 판단하여 노이즈에 휘둘리지 않는 강건함을 갖추는 것이 실무적으로 매우 중요하다는 점을 강조하고 있습니다.


마지막으로 제공해주신 이미지(image_a06abf.png)는 RAG 시스템의 노이즈 문제를 해결하기 위한 RetRobust: Training Free 기법의 핵심 원리와 예시를 다루고 있습니다. 이 자료의 내용을 정리해 드립니다.
RetRobust: Training Free (학습 없는 강건한 RAG)
이 기법은 별도의 모델 학습 없이 기존의 자연어 추론(Natural Language Inference, NLI) 모델을 활용하여 검색된 정보의 논리적 타당성을 검증합니다.
1. 핵심 개념: NLI 모델 활용
- 정의: NLI는 주어진 **전제(Premise)**를 바탕으로 **가설(Hypothesis)**이 참(함축), 거짓(모순), 또는 중립인지를 판별하는 태스크입니다.
- 성능: 현재 SOTA(최고 수준) NLI 모델들은 92% 이상의 높은 정확도를 보여주어 신뢰할 수 있는 검증 도구로 활용됩니다.
2. RAG에 적용하는 논리 구조
시스템은 검색된 문서가 실제 정답을 뒷받침하는지 다음과 같이 대응시켜 판단합니다:
- 전제 (Premise): 검색된 문서 조각(Retrieved passage)
- 가설 (Hypothesis): 사용자의 질문(Question)과 그에 대한 모델의 답변(Answer) 쌍
3. 작동 메커니즘 (의사결정 루프)
- 검증: 올바른 검색 결과라면, 검색된 문서(전제)가 질문과 답변(가설)을 논리적으로 **함축(Entailed)**해야 합니다.
- 선택적 답변:
- 함축 시: 검색된 정보를 신뢰하여 답변 생성에 포함합니다.
- 미함축 시: 검색된 문서가 질문과 무관하거나 틀렸다고 판단되면, 이를 무시하고 **LLM의 내부 지식만을 이용한 직접 답변(Direct answering)**으로 전환합니다.
이미지 요약 인사이트: 이 자료의 핵심은 **"검색 결과가 오히려 독이 되는 상황을 논리로 차단하자"**는 것입니다. 이미지 하단의 예시처럼, "제너럴 호스피털" 관련 질문에 대해 엉뚱한 배우 정보가 검색되었을 때, NLI 모델이 이를 '함축되지 않음'으로 걸러내어 LLM이 원래 알고 있던 정확한 정보(Steve Burton)를 유지하게 만드는 것이 이 기술의 목표입니다.


RetRobust: Small Training (소량의 데이터 학습을 통한 강건한 RAG)
이 기법은 LLM이 무관한 문맥(Irrelevant contexts)을 스스로 무시할 수 있도록 적은 양의 데이터를 활용해 미세 조정(Fine-tuning)하는 방식입니다.
1. 동기 및 문제 의식 (Motivation)
- 기존 방식의 한계: NLI 등을 활용해 문서를 걸러내는 이전의 방식은 기준이 너무 엄격하여, 실제로 도움이 될 수 있는 관련 문서까지 버려지는 경우가 발생할 수 있습니다.
- 핵심 과제: 주어진 질문에 대해 관련 있는 패시지와 관련 없는 패시지를 모두 수집하여 모델이 이를 구분하게 만드는 것입니다.
2. 데이터셋 구축 방법 (How to construct dataset?)
모델을 학습시키기 위해 다음과 같이 관련성 있는 데이터와 없는 데이터를 정의합니다:
- 관련 패시지 (Relevant): 현재 검색기(Retriever)가 찾은 가장 상위(Top-1) 문서.
- 무관 패시지 (Irrelevant): 다음 두 가지 중 하나를 선택합니다.
- 해당 질문에 대해 검색 결과의 가장 하위(Bottom-K)에 있는 문서.
- 아예 다른 질문에 대한 상위(Top-K) 문서.
3. 학습 목표 및 효과 (Training Goal)
- 정답 우도 극대화: 수집된 데이터를 바탕으로 모델이 정답을 맞힐 확률(Likelihood)을 높이도록 미세 조정합니다.
- 강건성 확보: 설령 검색기가 잘못된 문서(Wrong retrieved passages)를 가져오더라도, 모델이 이를 비판적으로 수용하여 정확한 예측을 내놓을 수 있게 합니다.
이미지 요약 및 인사이트: 이 자료는 앞서 살펴본 '학습 없는 방식(Training Free)'이 너무 보수적일 수 있다는 점을 보완합니다. 소량의 학습 데이터를 통해 모델에게 "어떤 정보가 진짜이고 가짜인지"를 직접 가르침으로써, 검색 품질이 낮아지는 최악의 상황에서도 시스템의 답변 정확도를 유지하려는 고도의 최적화 전략을 보여줍니다.

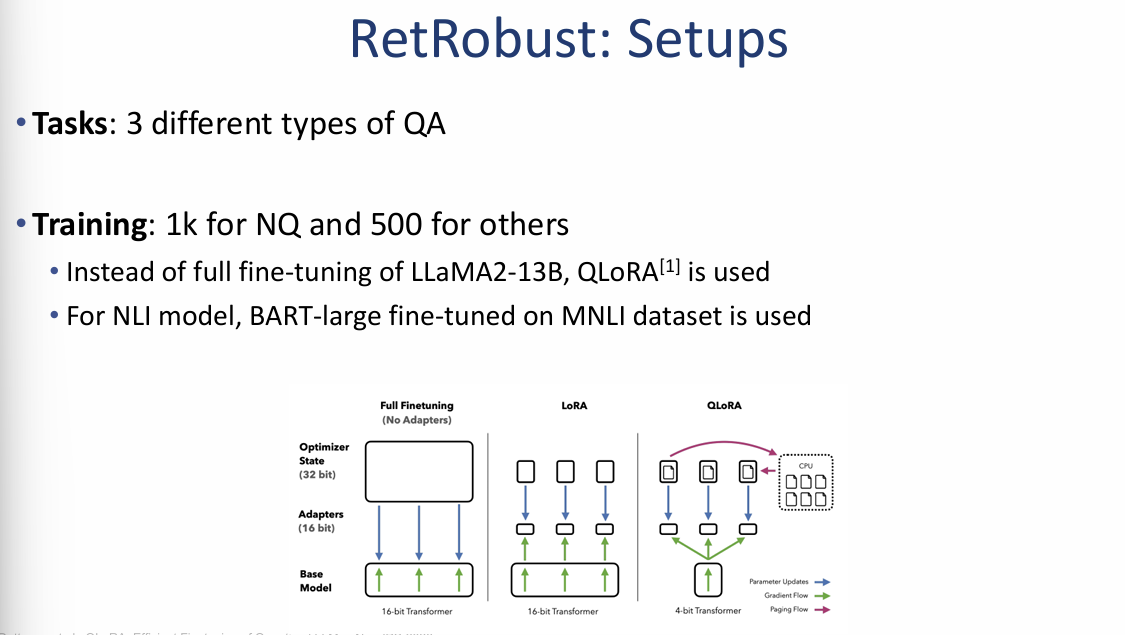
RetRobust: 실험 설정 (Setups)
이 자료는 RetRobust 기법의 성능을 검증하기 위해 사용된 다양한 질의응답(QA) 태스크와 학습 상세 정보를 포함하고 있습니다.
1. 3가지 유형의 질의응답 태스크 (Tasks)
실험은 난이도와 추론 방식에 따라 총 5개의 데이터셋을 활용했습니다.
- Single-hop QA: 단일 문서 검색만으로 답변 가능한 질문 (예: Natural Question (NQ)).
- Multi-hop QA (명시적 추론): 여러 단계를 거친 논리적 추론이 필요한 질문 (예: 2WikiMQA, Bamboogle).
- Multi-hop QA (상식 기반): 상식과 복합적인 추론이 결합된 질문 (예: StrategyQA, Fermi).
2. 학습 상세 정보 (Training)
모델을 효율적으로 학습시키기 위한 구체적인 방법론을 제시합니다.
- 데이터 규모: NQ 데이터셋은 1,000개, 나머지 데이터셋은 각 500개의 소규모 데이터를 사용해 학습했습니다.
- 효율적 미세 조정: LLaMA2-13B 모델 전체를 튜닝하는 대신, 메모리 효율적인 QLoRA 기법을 적용했습니다.
- NLI 모델: 검증을 위한 NLI 모델로는 MNLI 데이터셋으로 미세 조정된 BART-large 모델을 사용했습니다.
3. 하드웨어 효율성 시각화
이미지 우측 하단은 Full Fine-tuning, LoRA, QLoRA의 차이를 보여줍니다.
- QLoRA: 4비트 양자화(4-bit Transformer)를 통해 파라미터 업데이트 양을 최소화하면서도 베이스 모델의 성능을 유지하는 가장 효율적인 구조임을 시각적으로 설명합니다.
이미지 요약 및 인사이트: 이 자료는 RetRobust가 단순한 이론에 그치지 않고, **소량의 데이터(500~1,000개)**와 **효율적인 학습 기법(QLoRA)**만으로도 다양한 난이도의 QA 태스크에서 실질적인 성능 향상을 거둘 수 있음을 증명하기 위한 구체적인 로드맵을 보여줍니다.


RetRobust: 실험 결과 및 분석 (Results)
실험 결과, RetRobust 기법은 검색 품질이 낮거나 노이즈가 섞인 상황에서도 모델의 성능 하락을 방지하고 정확도를 일관되게 향상시키는 것으로 나타났습니다.
1. Top-1 검색 성능 (QA with Top-1 retrieval)
가장 관련성이 높은 문서 1개를 가져왔을 때의 성능 비교입니다.
- 성능 방어: NLI 모델을 활용한 검증 방식(In-Context RALM + NLI)이 잘못된 정보에 의한 성능 저하를 성공적으로 방지했습니다.
- 추가 학습의 효과: 소량의 데이터로 미세 조정한 모델(Trained RALM (RetRobust))은 기본 모델보다 훨씬 더 큰 폭의 성능 향상을 보였습니다.
- 예시: 2WikiMQA 데이터셋에서 기본 모델 대비 성능이 +34.9 포인트 상승하며 가장 드라마틱한 개선을 보였습니다.
2. 다양한 검색 시나리오 대응
검색 품질이 떨어지는 최악의 상황(낮은 순위 문서 검색 또는 무작위 검색)에서의 강건성을 테스트했습니다.
- 저품질 검색 (Low-rank retrieval): 검색 순위가 낮은 문서를 가져왔을 때 발생하는 리스크를 RetRobust가 효과적으로 완화했습니다.
- 무작위 검색 (Random retrieval): 질문과 아예 상관없는 문서가 들어온 상황에서도, 모델이 이를 무시하고 직접 답변함으로써 성능 하락폭을 최소화했습니다.
- 예시: NQ 데이터셋에서 무작위 검색 시 기본 모델은 -7.6의 성능 하락을 보였으나, RetRobust 학습 모델은 오히려 +4.2의 성적을 유지했습니다.
3. 학습 데이터 유무에 따른 차이
- 학습 데이터 포함 그룹 (NQ, 2WikiMQA 등): 직접적인 미세 조정을 통해 압도적인 성능 향상을 기록했습니다.
- 학습 데이터 미포함 그룹 (Bamboogle, Fermi): 직접 학습하지 않은 태스크에서도 NLI 검증 방식이 성능 하락을 막아주는 제로샷 강건성을 입증했습니다.
이미지 요약 및 인사이트: 이 데이터는 RetRobust가 단순히 "정답률을 높이는 것"을 넘어, **"검색 결과가 나쁠 때 시스템이 망가지는 것을 막아주는 안전장치"**로서 매우 강력하다는 점을 시사합니다. 특히 QLoRA를 통한 소량의 학습이 병행될 때, 노이즈가 많은 실제 웹 환경에서도 가장 안정적인 RAG 시스템을 구축할 수 있음을 보여줍니다.

RAG의 문제점 및 해결을 위한 학습의 동기
이 자료는 RAG 시스템 운영 중 관찰된 두 가지 핵심 결함과 이를 추가 학습(Additional training)을 통해 직접적으로 해결하려는 목적을 제시합니다.
1. RAG의 주요 관찰 문제점 (Issues in RAG)
- 적응적 적용의 부재: RAG는 모든 질문에 일률적으로 적용되기보다는, 질문의 특성이나 난이도에 따라 적응적으로(adaptively) 적용되어야 할 필요가 있습니다.
- 근거 없는 답변 생성 (Not Grounded): RAG를 사용함에도 불구하고, 모델이 생성한 답변이 실제 검색된 문서의 내용에 기반하지 않고 모델 내부의 잘못된 지식이나 환각에 의존하는 경우가 발생합니다.
2. 해결을 위한 동기 (Motivation)
- 추가 학습의 필요성: 위와 같은 RAG의 고질적인 문제들을 **추가 학습(Additional training)**을 통해 직접적으로 해결할 수 있는지 탐구합니다.
- 딥러닝의 직접적 해결책: 딥러닝에서 발생하는 문제들을 해결하는 가장 직접적이고 확실한 방법은 바로 **학습(Training)**임을 강조합니다.
이미지 요약 인사이트: 이 자료는 RAG가 단순히 외부 지식을 '가져오는' 단계를 넘어, 모델이 검색 결과를 얼마나 비판적으로 수용하고 질문에 맞춰 유연하게 반응할 수 있도록 **미세 조정(Fine-tuning)**하는 단계로 진화해야 함을 시사합니다.

강화 학습을 통한 적응형 RAG 학습 (Learn Adaptive RAG via RL)
이 자료는 모델이 스스로 검색이 필요한 시점을 판단하고 결과의 질을 평가하는 '적응형 능력'을 어떻게 학습시킬 것인가에 대한 진화 과정을 보여줍니다.
1. Self-RAG와 지도 미세 조정 (SFT)
- 기존 방식: Self-RAG는 지도 미세 조정(SFT, Supervised Fine-Tuning)을 사용하여 LLM이 적응형 RAG 능력을 갖추도록 학습시킵니다.
- 핵심 질문: 이 과정을 RLHF(인간 피드백 기반 강화 학습)와 유사한 **강화 학습(Reinforcement Learning)**을 통해 더 개선할 수 있을까요?
2. 강화 학습(RL)의 도입과 최신 동향
- 긍정적 답변: 예, 가능합니다. 특히 최근 DeepSeek와 같은 기업들이 이러한 강화 학습 방법론을 채택하고 있는 것으로 보입니다.
- 실제 사례: 이미지 하단에는 DeepSeek 인터페이스가 제시되어 있으며, 모델이 답변 생성 시 스스로 'DeepThink(추론)' 모드를 가동하거나 **'Search(검색)'**를 선택하는 등의 적응형 동작을 강화 학습을 통해 최적화했음을 시사합니다.
종합 요약 및 인사이트
이 자료의 핵심은 RAG가 단순히 "문서를 가져와서 읽는 것"에서 벗어나, 모델이 **"지금 내 지식으로 충분한가? 아니면 검색이 필요한가?"**를 스스로 판단하도록 만드는 것입니다. 이를 위해 과거의 단순한 정답지 학습(SFT)을 넘어, 시행착오를 통해 최적의 행동을 배우는 **강화 학습(RL)**이 새로운 표준으로 자리 잡고 있음을 보여줍니다.


마지막으로 제공해주신 이미지(image_a0d7d4.png)는 강화 학습(RL)을 활용하여 적응형 RAG를 구현하는 오픈 소스 프레임워크인 Search-R1의 핵심 구조와 작동 원리를 다루고 있습니다. 해당 자료의 내용을 정리해 드립니다.
Search-R1: RL 기반 적응형 RAG 프레임워크
Search-R1은 DeepSeek-R1 프레임워크를 기반으로 하여, 모델이 답변 생성 과정에서 스스로 추론하고 검색을 호출하는 능력을 배우도록 설계되었습니다.
1. 핵심 아이디어: 특수 토큰을 활용한 RAG 통합
Search-R1은 모델이 출력 텍스트 내에서 특정 **특수 토큰(Special tokens)**을 생성함으로써 RAG의 각 단계를 제어하게 합니다.
- 추론 토큰 (<think> ... </think>): 모델의 내부 사고 및 추론 과정을 기록합니다.
- 검색 호출 토큰 (<search> query </search>): 필요한 정보를 찾기 위해 검색 엔진에 쿼리를 날립니다.
- 검색 결과 토큰 (<information> docs </information>): 검색 엔진으로부터 가져온 외부 문서 내용을 입력받습니다.
- 최종 답변 토큰 (<answer> answer </answer>): 모든 정보를 종합하여 최종적인 정답을 도출합니다.
2. 강화 학습을 위한 보상 모델 (Reward Models)
모델이 적절한 시점에 검색을 사용하고 올바른 답변을 내도록 두 가지 보상을 통해 학습시킵니다.
- 정확도 보상 (Accuracy rewards): 최종 답변이 정답과 일치하는지 평가합니다. 수학 문제처럼 결과가 명확한 경우 규칙 기반 검증을 활용하며, 코딩 문제의 경우 컴파일러와 테스트 케이스를 통해 피드백을 생성합니다.
- 형식 보상 (Format rewards): 모델이 생각하는 과정을 반드시 <think> 태그 내에 포함하도록 형식을 강제하여 추론 능력을 극대화합니다.
종합 요약 및 인사이트
Search-R1의 핵심은 **"모델이 언제 검색을 할지 스스로 생각하게 하는 것"**입니다. 단순히 외부 문서를 프롬프트에 넣어주는 기존 방식을 넘어, 모델이 추론(Reasoning) 과정에서 지식의 부족을 느끼면 스스로 <search> 토큰을 생성해 정보를 보충하도록 강화 학습을 통해 훈련시킨 진보된 형태의 RAG 모델입니다.


1. 적응형 RAG와 강화 학습 (Learn Adaptive RAG via RL)
최신 RAG 기술은 모델이 스스로 검색의 필요성을 판단하는 방향으로 진화하고 있습니다.
- 학습 방식의 진화: 기존 Self-RAG가 지도 미세 조정(SFT)을 사용했다면, 최근에는 RLHF와 유사한 **강화 학습(Reinforcement Learning)**을 통해 적응형 능력을 고도화하고 있습니다.
- 실제 사례: DeepSeek과 같은 최신 모델들이 이러한 강화 학습 기반의 적응형 RAG(추론 및 검색 모드 선택)를 채택하고 있는 것으로 보입니다.
2. Search-R1 프레임워크
Search-R1은 DeepSeek-R1 프레임워크를 따라 강화 학습을 통해 적응형 RAG를 배우는 오픈 소스 프레임워크입니다.
- 특수 토큰을 통한 제어: 모델은 출력 텍스트 내에 특수 토큰을 생성하여 RAG 과정을 스스로 제어합니다:
- <think>: 내부 추론 과정 기록.
- <search>: 외부 검색 엔진 호출을 위한 쿼리 생성.
- <information>: 검색된 외부 문서 내용 수집.
- <answer>: 최종 답변 도출.
- 보상 모델 (Rewards):
- 정확도 보상: 수학(규칙 기반 검증)이나 코딩(컴파일러 테스트) 문제에서 최종 답변의 정답 여부를 평가합니다.
- 형식 보상: 추론 과정을 반드시 <think> 태그 안에 포함하도록 유도합니다.
3. Search-R1 작동 예시 및 특징
강화 학습을 거친 모델은 질문의 난이도에 따라 유연하게 대처합니다.
- 자동화된 전략 수립: 강화 학습 과정에서 교차된 추론(Interleaved CoT)과 검색 전략이 자동으로 발현됩니다.
- 추론과 검색의 반복: 예시에서 모델은 초기 추론 중 지식이 부족함을 느끼면 <search>를 통해 정보를 확인하고, 다시 이를 바탕으로 심화 추론을 진행하여 최종 답변인 "McComb, Mississippi"를 정확히 도출해냅니다.
종합 요약: 최신 RAG 기술의 핵심은 모델에게 단순히 정보를 넣어주는 것이 아니라, **강화 학습(RL)**을 통해 모델 스스로 "어느 시점에 어떤 정보를 찾아야 하는지" 생각하게 만드는 것입니다. Search-R1은 이러한 추론과 검색의 상호작용을 특수 토큰과 보상 모델을 통해 체계화한 선도적인 사례입니다.


Search-R1: 보상 모델 및 학습 알고리즘
Search-R1은 모델이 스스로 추론하고 검색을 호출하는 최적의 전략을 배울 수 있도록 단순하면서도 강력한 보상 체계를 활용합니다.
1. 보상 모델 (How to reward?)
- 단순 결과 보상 (Simple outcome reward): 복잡한 형식 보상 없이, 모델이 내놓은 최종 답변($a_{pred}$)이 실제 정답($a_{gold}$)과 일치하는지만을 평가하는 EM(Exact Match) 방식을 사용합니다.
- 구조적 준수: 이미 강력한 구조적 준수 능력을 보인 LLM을 기반으로 하기 때문에 별도의 형식 보상(Format rewards)을 사용하지 않아도 모델이 태그 규격을 잘 따릅니다.
- 수식: $r_{\phi}(x, y) = EM(a_{pred}, a_{gold})$
2. 학습 알고리즘 및 목적 함수 (How to train?)
- 강화 학습 알고리즘: 기존의 강력한 RL 알고리즘인 PPO 또는 GRPO를 그대로 활용하여 학습할 수 있습니다.
- 최적화 목표: 모델이 정답을 맞힐 확률을 극대화하면서도, 참조 모델(Reference model)과의 급격한 변화를 방지하기 위한 KL 발산(KL Divergence) 페널티를 적용합니다.
- 학습 대상의 이원화: 모델의 답변 생성($y$)은 LLM에 의한 직접 생성과 검색(Retrieval) 결과라는 두 가지 경로를 모두 포함하며, 강화 학습은 이 과정 전체를 최적화합니다.
3. 학습을 통해 발현된 지능적 행동
- 자동 발현된 전략: 강화 학습 과정에서 명시적으로 가르치지 않았음에도 불구하고, **추론과 검색이 교차(Interleaved CoT & Retrieval)**되는 고도의 전략이 스스로 발현됩니다.
- 검색의 선순환: 모델은 초기 추론을 시도하다가 지식이 부족하면 <search>를 호출하고, 돌아온 <information>을 바탕으로 다시 <think>(심화 추론)를 진행하여 정확한 답변을 도출해냅니다.
종합 요약 및 마무리:
Search-R1의 핵심은 **"단순한 정답 여부에 대한 보상만으로도 모델이 언제 검색을 하고 어떻게 생각해야 할지 스스로 배우게 만든 것"**입니다. 이는 복잡한 지도 미세 조정 없이도 강화 학습(RL)을 통해 RAG 시스템의 지능을 비약적으로 높일 수 있음을 보여줍니다.


Search-R1: 학습 목적 함수 및 추론 알고리즘 (image_a0db3a.png 참조)
마지막 이미지에서 다루는 내용은 Search-R1이 강화 학습을 통해 최적의 검색 시점을 배우는 수학적 원리와 실제 서비스 시의 작동 로직입니다.
1. 강화 학습 목적 함수 (Training Objective)
모델은 검색을 통해 정답률을 높이면서도 기존 지식과의 균형을 맞추기 위해 다음 수식을 최적화합니다.
- 보상 극대화: 모델 생성 답변($y$)과 외부 검색($\mathcal{R}$) 결과가 결합되었을 때, 실제 정답을 맞힐 확률($r_\phi$)을 최대화합니다.
- KL 발산 페널티: 새로운 정책($\pi_\theta$)이 기존 참조 모델($\pi_{ref}$)에서 너무 급격하게 변하지 않도록 규제하여 학습의 안정성을 도모합니다.
- 손실 계산 최적화: 검색 결과로 삽입된 정보(<information>) 부분은 모델이 직접 생성한 것이 아니므로, 손실 계산(Loss calculation)에서 제외하여 학습 효율을 높입니다.
2. 추론 알고리즘 (Inference Algorithm)
실제 구동 시 모델은 다음과 같은 '멀티턴 검색 루프'를 수행합니다.
- 토큰 생성: 응답 토큰을 하나씩 생성하며 진행합니다.
- 검색 트리거: 생성 도중 <search> 태그가 감지되면 즉시 생성을 중단하고 검색 쿼리를 추출합니다.
- 정보 주입: 검색 엔진으로부터 받은 결과($d$)를 <information> 태그와 함께 컨텍스트에 삽입합니다.
- 반복 및 종료: 설정된 검색 예산($B$) 한도 내에서 위 과정을 반복하며, 최종적으로 <answer> 태그가 나오면 전체 응답을 완료합니다.
요약 인사이트:
이 자료의 핵심은 모델이 단순히 정보를 전달받는 수동적 입장에서 벗어나, 정답 보상을 받기 위해 스스로 어느 타이밍에 어떤 정보를 검색해야 할지 수학적으로 최적화한다는 점에 있습니다.
브로드
그레디언트 누적
딥러닝 모델을 학습시킬뗴 각 배치마다 모델을 업데이트하지 않고 여러 베치ㅡ이 학습 데이터를 연산한 후 그레
분산학습
PEFT : LoRA
부분만 학습함
학습방법-
r값(랭크)
alpha 값
target-modules

#드라이브 용량보기
df -h
cd ~/.cache
허깅 페이스 모델을 다운받으면 이 위치에 저장됨
du -h --max-depth=1
폴더별로 용량 확인
rm -rf ./huggingface/
encoding='utf-8-sig'를 사용해야 엑셀에서 깨지지않고 열수있
#도커를 사용하여 redis(캐시) 설치하기
docker run -d --name redis -p 6379:6379 redis
pip install redis
'AI > LLM' 카테고리의 다른 글
| [RLHF] 인간의 가치 정렬 (0) | 2025.07.25 |
|---|---|
| [SFT] 지시어 이행 학습 (0) | 2025.07.24 |
| [Tokenizer] 언어를 쪼개는 기술 (0) | 2025.07.22 |
| [In-Context Learning] 맥락의 힘 (0) | 2025.07.21 |
| [Prompting] 프롬프트 엔지니어링 Ⅰ (0) | 2025.07.18 |