이번 단계는 무뚝뚝한 백과사전 같던 베이스 모델에게 '대화의 예절'과 '질문의 의도'를 가르치는 [SFT] 지시어 이행 학습입니다. 이 과정을 거쳐야만 모델은 비로소 우리가 흔히 아는 '챗봇'의 형태를 갖추게 됩니다.
[LLM 컨셉] SFT: 베이스 모델에게 '대화법'을 가르치다
**SFT (Supervised Fine-Tuning, 지도 미세 조정)**는 사전 학습(Pre-training)을 마친 베이스 모델을 특정 형식의 데이터셋으로 다시 한번 학습시키는 과정입니다. 베이스 모델이 "다음 단어를 맞히는 천재"라면, SFT를 거친 모델은 **"사람의 지시(Instruction)에 따라 정답을 내놓는 비서"**가 됩니다.
1. 왜 SFT가 필요한가?
사전 학습된 베이스 모델은 인터넷의 모든 글을 읽었기 때문에, 질문을 던지면 답을 하기보다 질문을 이어 쓰려는 습성이 있습니다.
- 사용자: "서울의 맛집 3곳을 추천해줘."
- 베이스 모델의 반응: "...라고 친구가 물어봤다. 나는 다음과 같이 대답할 준비를 했다. 첫 번째 맛집은..." (질문에 대답하지 않고 문장을 이어감)
SFT는 이러한 모델에게 [지시(Prompt) - 답변(Response)] 쌍으로 구성된 고품질 데이터를 학습시켜, 사용자의 요청에 곧바로 반응하도록 행동 양식을 교정합니다.
2. SFT 학습 데이터의 구조
SFT 데이터셋은 사람이 직접 작성하거나 검수한 정답지가 포함된 데이터입니다. 보통 다음과 같은 형식을 가집니다.
- Instruction (지시): 사용자가 시키는 일 (예: "다음 글을 요약해", "파이썬 코드를 짜줘")
- Input (입력): 지시 수행에 필요한 추가 정보 (예: 요약할 본문 내용)
- Output (출력): 모델이 내놓아야 할 이상적인 정답 (사람이 작성함)
3. SFT의 학습 과정
- 데이터 수집: 수만 건에서 수십만 건의 고품질 [지시-답변] 쌍을 준비합니다.
- Fine-tuning: 베이스 모델의 가중치를 이 데이터셋에 맞춰 미세하게 업데이트합니다.
- 학습 결과: 이제 모델은 질문을 받으면 "아, 이제 내가 답을 할 차례구나!"라고 인식하고 정해진 포맷(예: 대화형)에 맞춰 답변합니다. 이를 명령어 기반 모델(Instruct Model) 혹은 **채팅 모델(Chat Model)**이라고 부릅니다.
4. SFT의 한계
SFT는 매우 강력하지만 두 가지 큰 숙제가 남습니다.
- 데이터 구축 비용: 고품질의 [지시-답변] 세트를 사람이 일일이 만드는 데는 엄청난 시간과 비용이 듭니다.
- 창의성과 도덕성의 부재: 모델은 단순히 학습 데이터의 패턴을 복사할 뿐입니다. 사람이 준 정답지에 없는 복잡한 윤리적 가치 판단이나, 아주 미세한 말투의 뉘앙스까지 제어하기는 어렵습니다.
5. [선생님의 심화 보충] SFT와 데이터의 질 (Less is More)
과거에는 SFT 데이터가 많을수록 좋다고 생각했지만, 최근 연구(LIMA 등)에 따르면 **"매우 정교하게 잘 쓰여진 1,000개의 데이터가 대충 만든 10만 개보다 낫다"**는 사실이 밝혀졌습니다. 모델에게 '무엇을 아는지' 가르치는 것은 사전 학습의 몫이고, SFT는 단지 **'어떤 스타일로 꺼내 쓸지'**만 알려주면 되기 때문입니다.
✍️ 공부를 마치며
SFT는 모델에게 '사회성'을 부여하는 단계입니다. 이제 모델은 우리가 시키는 일을 알아듣고 수행할 수 있게 되었습니다. 하지만 아직 모델이 '가장 선호되는 답변'이 무엇인지, 혹은 '나쁜 대답'을 어떻게 피해야 하는지는 모릅니다. 이를 위해 다음 단계인 **강화학습(RLHF)**이 필요합니다.

딥러닝 모델의 평가 (Evaluation of Deep Learning Model)
딥러닝 시스템의 성능을 객관적으로 파악하기 위해서는 모델이 학습 과정에서 경험하지 못한 데이터를 통해 검증하는 과정이 필수적입니다.
1. 테스트 데이터의 정의 (Test Data)
- 핵심 원칙: 평가는 반드시 **"테스트 데이터(test data)"**를 기반으로 이루어져야 합니다.
- 특성: 테스트 데이터는 학습 시 사용된 데이터와 동일한 태스크 및 분포를 가지지만, 학습 중에는 단 한 번도 노출되지 않은(never seen during training) 데이터여야 합니다.
2. 구체적인 평가 예시 (Sentiment Classification)
이미지는 감성 분류(Sentiment classification) 태스크를 수행하는 미세 조정된 언어 모델(예: BERT)의 평가 과정을 보여줍니다.
- 입력(Input): "전체적으로 영화는 끔찍했다(The movie was terrible)"와 같은 실제 사용자 리뷰 문장이 입력됩니다.
- 모델(Fine-tuned LM): 사전 학습(Pre-training) 후 특정 목적에 맞게 미세 조정(Fine-tuning)된 BERT 모델이 이 문장을 처리합니다.
- 출력(Output): 모델은 문장의 맥락을 분석하여 최종적으로 **"부정적(Negative)"**이라는 분류 결과를 내놓습니다.
이미지 요약 인사이트: 이 자료의 핵심은 딥러닝 모델의 '진정한 실력'을 확인하기 위해 학습 데이터와 분리된 독립적인 테스트 셋이 왜 필요한지를 강조하는 데 있습니다. 모델이 단순히 데이터를 외운 것인지(Overfitting), 아니면 새로운 문장에 대해서도 올바른 판단을 내릴 수 있는 일반화 능력을 갖췄는지를 확인하는 표준적인 절차를 설명하고 있습니다.


LLM의 평가 및 태스크 적응 (Evaluation of LLM)
거대 언어 모델은 방대한 양의 텍스트 데이터를 통해 학습되었기 때문에, 적절한 지시와 예시만 있다면 사전 학습 시 명시되지 않은 새로운 태스크에도 유연하게 적응할 수 있습니다.
1. 인스트럭션과 예시를 통한 적응 (In-context learning)
- 범용성: LLM은 질문 답변(QA), 요약, 코드 생성 등 매우 다양한 태스크를 수행할 수 있도록 훈련되었습니다.
- 적응 방식: 모델의 파라미터를 직접 업데이트(Gradient updates)하지 않고도, **지시어(Instruction)**와 **몇 가지 예시(Examples)**를 포함한 프롬프트를 제공하는 것만으로 모든 태스크에 적응이 가능합니다.
- 예시 (Few-shot): 영어를 프랑스어로 번역하는 작업에서, 몇 개의 번역 쌍을 보여준 뒤 새로운 단어의 번역을 요구하는 방식입니다.
2. 성능을 결정하는 2가지 핵심 요소: 입력 프롬프트
모델의 성능을 극대화하기 위해서는 입력하는 프롬프트의 품질이 매우 중요합니다.
- 상세한 지침 (Detailed instruction): 모델이 수행해야 할 역할을 명확하게 규정할수록 더 나은 성능을 보입니다.
- 예시의 품질과 수:
- 더 좋은 예시와 더 많은 수의 예시를 제공할수록 정확도(Accuracy)가 향상됩니다.
- 특히, 이미지 내 그래프를 보면 **무작위로 선택된 예시(Randomly selected examples)**보다 **리트리버를 통해 질문과 유사한 문맥을 찾아 제공한 예시(Retrieved examples)**를 사용할 때 성능 지표가 훨씬 더 가파르게 상승함을 확인할 수 있습니다.
이미지 요약 인사이트: 이 자료의 핵심은 **"모델을 새로 학습시키는 것보다 잘 짜여진 프롬프트가 더 효율적일 수 있다"**는 점입니다. 질문과 가장 관련 있는 예시를 실시간으로 찾아 프롬프트에 넣어주는 방식이 LLM의 잠재력을 끌어올리는 가장 강력한 도구임을 강조하고 있습니다.


LLM 평가의 핵심 요소: 프롬프트와 디코딩 (Evaluation of LLM)
거대 언어 모델의 성능을 제대로 이끌어내기 위해서는 단순히 질문을 던지는 것을 넘어, 모델의 추론 방식과 출력 성향을 정밀하게 제어해야 합니다.
1. 입력 프롬프트의 진화: Chain-of-Thought (CoT)
복잡한 논리 구조가 필요한 태스크를 해결하기 위해서는 단계별 추론 과정을 포함하는 Chain-of-Thought(CoT) 프롬프팅이 필수적입니다.
- 작동 방식: 정답만 알려주는 대신, "왜 그런 결과가 나왔는지"에 대한 중간 추론 과정을 예시로 제공합니다.
- 효과: PaLM 모델의 사례를 보면, 모델 규모가 커질수록 CoT를 적용했을 때의 문제 해결 능력이 일반적인 방식(Standard)보다 훨씬 가파르게 상승하여 미세 조정된 SOTA 모델의 성능에 근접함을 확인할 수 있습니다.
2. 두 번째 핵심 요소: 디코딩 방법 (Decoding method)
모델이 답변을 생성하는 방식인 디코딩 설정을 통해 출력의 다양성을 조절할 수 있습니다.
- 온도(Temperature) 설정: 모델의 출력값에 대한 확률 분포를 조절하는 매개변수입니다.
- 주의사항:
- Temperature > 0일 때, 모델은 동일한 질문에 대해서도 매번 서로 다른 답변을 생성(Sampling)할 수 있습니다.
- 일관된 정답이 필요한 태스크(수학 등)에서는 낮은 온도를, 창의적인 답변이 필요한 태스크에서는 높은 온도를 사용하는 것이 권장됩니다.
이미지 요약 인사이트: 이 자료는 LLM의 성능이 단순히 모델의 크기에만 의존하는 것이 아니라, **"생각하는 법을 가르치는 프롬프트(CoT)"**와 **"답변의 일관성을 제어하는 설정(Temperature)"**을 얼마나 잘 활용하느냐에 달려 있음을 강조합니다.
LLM 평가의 핵심 요소: 프롬프트와 디코딩 (Evaluation of LLM)
거대 언어 모델의 성능을 제대로 이끌어내기 위해서는 단순히 질문을 던지는 것을 넘어, 모델의 추론 방식과 출력 성향을 정밀하게 제어해야 합니다.
1. 입력 프롬프트의 진화: Chain-of-Thought (CoT)
복잡한 논리 구조가 필요한 태스크를 해결하기 위해서는 단계별 추론 과정을 포함하는 Chain-of-Thought(CoT) 프롬프팅이 필수적입니다.
- 작동 방식: 정답만 알려주는 대신, "왜 그런 결과가 나왔는지"에 대한 중간 추론 과정을 예시로 제공합니다.
- 효과: PaLM 모델의 사례를 보면, 모델 규모가 커질수록 CoT를 적용했을 때의 문제 해결 능력이 일반적인 방식(Standard)보다 훨씬 가파르게 상승하여 미세 조정된 SOTA 모델의 성능에 근접함을 확인할 수 있습니다.
2. 두 번째 핵심 요소: 디코딩 방법 (Decoding method)
모델이 답변을 생성하는 방식인 디코딩 설정을 통해 출력의 다양성을 조절할 수 있습니다.
- 온도(Temperature) 설정: 모델의 출력값에 대한 확률 분포를 조절하는 매개변수입니다.
- 주의사항:
- Temperature > 0일 때, 모델은 동일한 질문에 대해서도 매번 서로 다른 답변을 생성(Sampling)할 수 있습니다.
- 일관된 정답이 필요한 태스크(수학 등)에서는 낮은 온도를, 창의적인 답변이 필요한 태스크에서는 높은 온도를 사용하는 것이 권장됩니다.
이미지 요약 인사이트: 이 자료는 LLM의 성능이 단순히 모델의 크기에만 의존하는 것이 아니라, **"생각하는 법을 가르치는 프롬프트(CoT)"**와 **"답변의 일관성을 제어하는 설정(Temperature)"**을 얼마나 잘 활용하느냐에 달려 있음을 강조합니다.


LLM 평가의 복잡성과 벤치마크 성능 (Evaluation of LLM)
거대 언어 모델은 특정 용도로만 쓰이는 것이 아니라 거의 모든 태스크에 적응할 수 있는 범용성을 가졌기 때문에, 그 성능을 객관적으로 측정하는 과정 또한 매우 복잡합니다.
1. 평가의 어려움 (Cons: Difficult to evaluate)
- 다양한 태스크: LLM은 질문 답변, 요약, 코딩 등 수많은 작업을 동시에 수행할 수 있습니다.
- 통합 테스트의 필요성: 모델의 진정한 실력을 파악하려면 이 수많은 태스크를 한꺼번에 테스트해야 하는데, 이는 평가 설계와 실행을 매우 어렵게 만드는 요인이 됩니다.
2. GPT-4의 학술 벤치마크 성능 예시
이미지 우측의 표는 OpenAI의 GPT-4 모델을 다양한 학술적 기준(Benchmark)으로 평가한 결과입니다.
- MMLU (지식): 5-shot 평가 기준 **86.4%**를 기록하며 GPT-3.5(70.0%)를 크게 앞질렀습니다.
- HellaSwag (상식 추론): **95.3%**의 높은 정확도로 일상적 상식 판단 능력을 입증했습니다.
- HumanEval (코딩): 0-shot 평가에서 **67.0%**를 기록, 이전 모델들(26~48%)에 비해 비약적인 코드 생성 능력 향상을 보여주었습니다.
- GSM-8K (수학): Chain-of-thought(CoT) 기법 적용 시 **92.0%**의 정확도로 복잡한 수학 문제 해결 능력을 보여주었습니다.
이미지 요약 인사이트: 이 자료의 핵심은 **"모델이 다재다능할수록 그 능력을 검증하는 잣대 또한 다각도로 정교해져야 한다"**는 점입니다. GPT-4의 사례처럼 언어 이해, 상식, 코딩, 수학 등 분야별 대표 벤치마크를 통해 모델의 강점과 한계를 명확히 수치화하는 과정이 LLM 평가의 표준임을 보여줍니다.


정답 기반 태스크와 MMLU 벤치마크 (Evaluation with Ground Truth)
공정한 모델 성능 비교를 위해, 오픈 소스 커뮤니티에서는 미리 정의된 정답(Ground truth)이 포함된 데이터셋을 활용하여 평가를 진행합니다.
1. 정답 기반 벤치마크의 특징 (Task with Ground Truth)
- 객관성 확보: 정답이 미리 정해져 있어 모델 간의 공정한 비교가 용이합니다.
- 다양성: 데이터셋에 따라 평가 방법과 성능 측정 지표(Metric)가 다를 수 있습니다.
- 플랫폼 활용: Hugging Face와 같은 플랫폼을 통해 MMLU(지식 측정), Xsum(요약 성능 측정) 등의 벤치마크 데이터를 쉽게 활용할 수 있습니다.
2. MMLU (Massive Multitask Language Understanding) 벤치마크
LLM의 종합적인 지식 수준을 측정하는 가장 대표적인 벤치마크입니다.
- 방대한 규모: 57개의 학술적 주제를 아우르는 16,000개의 객관식 문제로 구성되어 있습니다.
- 다루는 분야: 미시경제학, 물리학, 대학 수학 등 고도의 전문 지식이 필요한 분야를 포함합니다.
- 파급력: 2024년 7월 기준 1억 건 이상의 다운로드를 기록할 만큼 전 세계적으로 가장 널리 사용되는 기준입니다.
이미지 요약 인사이트: 이 자료의 핵심은 모델의 지적 능력을 평가할 때 **"이미 정해진 정답을 얼마나 정확하게 맞히는가"**를 표준적인 잣대로 삼는다는 점입니다. 특히 MMLU는 모델이 단순한 언어 생성을 넘어 대학 수준의 전문 지식을 실제로 이해하고 있는지를 판가름하는 핵심 지표임을 보여줍니다.


MMLU 벤치마크 평가 방식 및 결과 (Task with Ground Truth: MMLU)
MMLU는 거대 언어 모델이 학부 수준의 방대한 지식을 얼마나 정확하게 이해하고 있는지를 수치화하는 표준 지표로 활용됩니다.
1. 평가 방법 및 지표 (Method & Metric)
- 평가 방식: Few-shot 프롬프팅을 사용합니다. 즉, 모델에게 문제의 예시를 몇 개 보여준 뒤 정답을 맞히게 하는 방식입니다.
- 측정 지표: 객관식 질문 답변(QA) 벤치마크에서 가장 일반적으로 사용되는 **평균 정확도(Average Accuracy, %)**를 지표로 삼습니다.
2. 주요 LLM의 MMLU 성능 비교 (5-shot 기준)
이미지는 2024년 기준 최고 수준 모델들의 지식 수준을 보여줍니다.
- Claude 3 Opus: **86.8%**로 가장 높은 성적을 기록했습니다.
- GPT-4: **86.4%**로 뒤를 잇고 있습니다.
- Gemini 1.0 Ultra: **83.7%**의 우수한 성능을 보입니다.
- GPT-3.5: **70.0%**를 기록하여 이전 세대 모델임을 보여줍니다.
3. 평가 시 주의사항 및 해결책 (Caution & Mitigation)
- 문제점: LLM이 답변할 때 특정 형식을 따르지 않거나 답변 내에 불필요한 패턴을 포함하는 경우가 자주 발생합니다.
- 해결책: 이를 완화하기 위해 **구체적인 지시어(Specific instruction)**를 프롬프트에 포함해야 합니다. 하지만 이 역시 완벽한 해결책은 아니므로 주의가 필요합니다.
이미지 요약 인사이트: 이 자료는 MMLU가 모델의 지식 수준을 판가름하는 강력한 도구임을 보여줌과 동시에, 정확한 평가를 위해서는 **적절한 예시(Few-shot)**와 **엄격한 형식 제어(Specific instruction)**가 필수적임을 강조합니다.

정답 기반 태스크: NQ (Natural Question) 데이터셋
NQ는 구글 검색 엔진에서 실제 사용자들이 입력한 질문들을 기반으로 만들어진 데이터셋으로, 모델의 실질적인 정보 추출 및 답변 생성 능력을 평가하는 데 사용됩니다.
1. 데이터셋 구성 및 특징
- 규모: 개발 및 테스트 용도로 7,830개의 예시가 포함되어 있습니다.
- 주석(Annotation): 각 질문에는 답변의 정확도를 높이기 위해 5가지 방식의 주석이 달려 있습니다.
- 평가 방식: 객관식 선택지 없이 모델이 직접 **긴 답변(Long answer) 또는 짧은 답변(Short answer)**을 생성해야 합니다.
2. 실제 질문-답변 예시
이미지는 NQ 벤치마크의 구체적인 작동 방식을 두 가지 예시로 보여줍니다.
- 예시 1 (인물 정보): "존 윌크스 부스의 머리 색깔은?"이라는 질문에 대해, 위키피디아 페이지에서 관련 내용을 찾아 "칠흑색(jet-black)"이라는 짧은 정답을 도출합니다.
- 예시 2 (기술 정보): "비행기 모드에서 전화를 걸거나 받을 수 있는가?"라는 질문에 대해 논리적인 긴 설명과 함께 "아니오(BOOLEAN:NO)"라는 명확한 짧은 정답을 생성합니다.
이미지 요약 인사이트: 이 자료의 핵심은 **"모델이 실제 세상의 복잡한 질문에 대해 얼마나 정확한 근거(위키피디아 등)를 바탕으로 답변할 수 있는가"**를 검증하는 것입니다. 앞서 살펴본 MMLU가 객관식 지식 수준을 측정했다면, NQ는 실제 검색 환경과 유사한 주관식 답변 능력을 정밀하게 평가하는 기준이 됩니다.
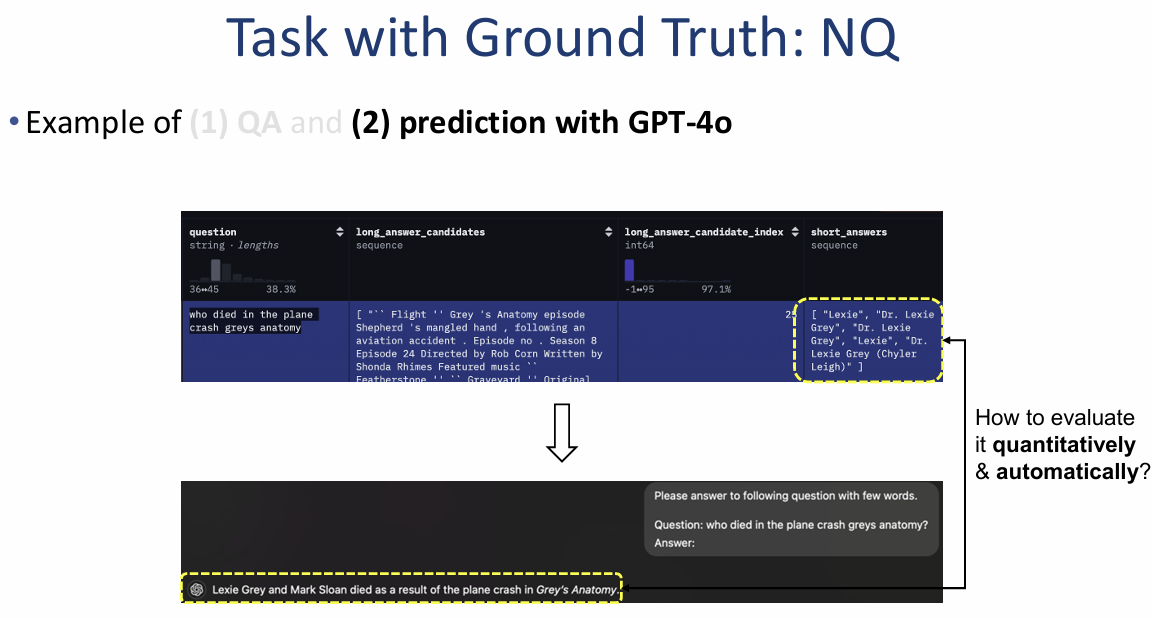

NQ 데이터셋의 정량적 평가 및 지표 (Task with Ground Truth: NQ)
주관식 답변은 객관식과 달리 텍스트의 일치 여부를 판단해야 하므로, 자동화된 정량 평가를 위해 어휘 일치(Lexical Matching) 기반의 지표를 활용합니다.
1. 자동 평가의 필요성 (How to evaluate quantitatively & automatically?)
- 문제 상황: GPT-4o와 같은 모델이 생성한 주관식 답변이 실제 정답 데이터셋(Ground truth)과 의미적으로는 같더라도 표현이 다를 수 있습니다.
- 해결책: 이를 자동으로 비교하기 위해 미리 정의된 수식과 알고리즘을 사용합니다.
2. 핵심 평가지표: EM 및 F1 스코어
- EM (Exact Match, 완전 일치):
- 기준: 모델의 예측값이 정답 문자열과 완벽하게 동일할 경우에만 1점, 그렇지 않으면 0점을 부여합니다.
- F1 스코어 (F1 Score):
- 기준: 단순 일치 여부를 넘어, 단어 단위(word-wise)로 비교하여 정밀도(Precision)와 재현율(Recall)의 조화 평균을 구합니다.
- Precision (정밀도): 모델이 뱉은 단어 중 실제 정답에 포함된 단어의 비율입니다.
- Recall (재현율): 실제 정답 단어 중 모델이 맞힌 단어의 비율입니다.
- 수식: $F_1 = \frac{2}{\text{recall}^{-1} + \text{precision}^{-1}}$
3. 평가 예시
- 질문: "지구상에서 자유 산소는 어디에서 발견되는가?"
- 예측값: "water bodies"
- 실제 정답: "in solution in the world's water bodies"
- 결과:
- EM: 0 (문자열이 완벽히 일치하지 않음)
- F1: 0.8 (대부분의 핵심 단어가 포함되어 높은 점수 획득)
이미지 요약 인사이트:
이 자료의 핵심은 **"주관식 답변도 수학적으로 평가할 수 있다"**는 점입니다. 특히 F1 스코어는 모델이 정답과 완전히 똑같이 말하지 않더라도, 얼마나 핵심 내용을 잘 포함하고 있는지를 유연하게 측정할 수 있는 강력한 도구가 됩니다.


정답 기반 태스크: XSum (Extreme Summarization) 데이터셋
XSum은 긴 문서의 핵심 내용을 단 한 문장으로 요약해야 하는 매우 높은 난이도의 요약 태스크를 평가하기 위해 설계되었습니다.
1. 데이터셋 구성 및 특징
- 규모: 약 **23만 개(230k)**의 방대한 뉴스 문서와 요약문 쌍으로 구성되어 있습니다.
- 요약 비율: 평균적으로 430개 단어 분량의 원문 데이터를 23개 단어 내외의 아주 짧은 한 문장으로 요약하는 것이 목표입니다.
- 난이도: 정보의 압축률이 매우 높기 때문에 모델의 핵심 문맥 파악 능력을 정밀하게 테스트할 수 있습니다.
2. 실제 요약 예시 및 출력 형태
이미지는 XSum 데이터셋이 Hugging Face와 같은 플랫폼에서 어떻게 보여지는지, 그리고 실제 모델이 어떤 결과물을 내놓는지 예시를 보여줍니다.
- 입력 데이터: 스코틀랜드 홍수 피해와 관련된 긴 뉴스 기사가 원문(Document)으로 제공됩니다.
- 모델 출력: 모델은 이 방대한 기사 내용을 분석하여 "스코틀랜드의 심각한 홍수로 인해 주택과 인프라가 파손되었으며, 더 빠른 경보 체계 구축에 대한 요구가 이어지고 있다"는 식의 함축적인 한 문장 요약을 생성합니다.
이미지 요약 인사이트: 이 자료의 핵심은 **"모델이 단순한 문장 복사를 넘어 전체 맥락을 얼마나 깊이 이해하고 압축할 수 있는가"**를 평가하는 것입니다. 앞서 살펴본 NQ가 정보 추출 능력을 본다면, XSum은 모델의 언어 이해 및 생성(Natural Language Generation) 능력의 극한을 시험하는 잣대가 됩니다.


요약 성능 평가 지표: ROUGE 스코어
ROUGE는 모델이 생성한 요약문(Generated)과 사람이 작성한 정답 요약문(Reference) 사이의 단어 또는 구문 중복도를 측정하여 품질을 평가합니다.
1. ROUGE의 핵심 원리
- 중복도 측정: 생성된 텍스트와 참조 텍스트 간에 단어가 얼마나 겹치는지를 계산합니다.
- ROUGE-N: N-gram(연속된 N개의 단어 뭉치)의 중복을 측정하는 방식입니다.
- ROUGE-1: 유니그램(Unigram, 단어 하나 단위)의 중복을 측정합니다.
- ROUGE-2: 바이그램(Bigram, 두 단어 조합 단위)의 중복을 측정합니다.
2. 평가 예시 (ROUGE-1 기준)
이미지는 실제 문장을 통해 ROUGE-1 스코어가 어떻게 계산되는지 보여줍니다.
- 참조 문장(Reference): "The cat sat on the mat." (총 6단어)
- 생성 문장(Generated): "The cat lay on the mat."
- 중복 단어: {"The", "cat", "on", "the", "mat"} (총 5단어 일치)
- 계산 결과: $5 / 6 = \mathbf{0.83}$
3. 태스크 적용: XSum 데이터셋
- XSum의 특성: 약 23만 개의 뉴스 데이터를 평균 430단어에서 23단어로 압축하는 '극한의 요약' 태스크입니다.
- 평가 과제: 이미지 좌측에서는 모델이 생성한 긴 설명 문장과 실제 정답(Ground Truth)인 짧은 요약문 사이의 유사도를 어떻게 측정할 것인가에 대한 화두를 던지며, 이에 대한 해답으로 ROUGE를 제시합니다.
종합 요약:
이 자료의 핵심은 요약 모델의 성능을 평가할 때 **"정답지의 단어를 얼마나 빠짐없이 포함하고 있는가(Recall)"**를 수학적으로 산출하는 방법을 설명하는 것입니다. 특히 ROUGE는 모델이 원문의 핵심 정보를 놓치지 않고 요약문에 잘 반영했는지를 확인하는 필수적인 잣대가 됩니다.

임베딩 공간을 활용한 의미적 유사도 평가 (Semantic Similarity)
단어의 중복도만 측정하는 ROUGE와 달리, 이 방식은 텍스트의 **수학적 의미(Semantics)**가 얼마나 유사한지를 벡터 간의 거리를 통해 계산합니다.
1. 평가 프로세스
- 텍스트 임베딩 (Mapping to embedding): 별도로 학습된 문장 인코더(Sentence Encoder)를 사용하여 원문 텍스트를 임베딩 공간의 벡터로 변환합니다.
- 유사도 측정 (Measuring distance): 변환된 벡터 간의 거리($L2$ 거리) 또는 각도(코사인 유사도, Cosine similarity)를 측정하여 두 문장이 얼마나 의미적으로 가까운지 평가합니다.
2. Sentence-BERT(SBERT) 활용 예시
이미지 하단의 도식은 BERT 모델을 활용해 두 문장의 유사도를 계산하는 표준적인 구조를 보여줍니다.
- 구조: 문장 A와 문장 B를 각각 BERT 레이어에 통과시킨 후, 풀링(Pooling) 과정을 거쳐 고정된 크기의 벡터 $u$와 $v$를 생성합니다.
- 결과: 생성된 두 벡터 사이의 코사인 유사도를 계산하여 -1에서 1 사이의 값으로 유사도를 산출합니다.
3. 주의사항 (Caution)
- 임베딩 품질: 이 평가 방식의 정확도는 사용된 문장 임베딩 모델의 품질에 전적으로 의존하므로, 신뢰할 수 있는 모델을 선택하는 것이 매우 중요합니다.
종합 요약 및 마무리:
이 자료는 텍스트 평가가 단순히 "똑같은 단어를 썼는가(ROUGE)"를 넘어 **"표현은 달라도 같은 의미를 담고 있는가(SBERT)"**로 진화하고 있음을 보여줍니다. 특히 의미 전달이 중요한 요약 태스크(XSum)에서 임베딩 기반 평가는 더욱 정밀한 성능 지표가 됩니다.


자유 형식 텍스트 생성 (Open-ended Text Generation)
이 태스크는 주어진 문맥(Context)을 바탕으로 논리적이고 일관된 텍스트를 계속해서 생성해내는 것을 목표로 합니다. LLM의 대부분의 출력은 이 범주에 속합니다.
1. 디코딩 방법별 생성 특징 (Visual Example)
이미지 좌측은 동일한 시작 문장에 대해 디코딩 알고리즘(Decoding Methods)이 달라짐에 따라 생성되는 결과물이 어떻게 변하는지 보여줍니다.
- Greedy/Beam Search: 가장 확률이 높은 단어만 선택하기 때문에 문장이 논리적일 수 있으나, 반복적인 패턴이 나타나거나 단조로워지는 경향이 있습니다.
- Sampling (Top-k, Top-p): 무작위성을 부여하여 훨씬 더 풍부하고 사람다운 문장을 생성하지만, 간혹 맥락을 벗어나는 위험이 있습니다.
2. 디코딩 방법별 성능 비교 지표 (Evaluation Results)
우측의 표는 다양한 디코딩 기법들의 정량적 성적을 보여줍니다.
- Perplexity (당혹도): 모델이 다음 단어를 얼마나 잘 예측하는지 나타내며, 값이 낮을수록 예측력이 좋습니다. **Greedy(1.50)**나 **Beam Search(1.48)**가 매우 낮지만, 이는 창의성 부족으로 이어질 수 있습니다.
- Self-BLEU4: 생성된 문장들 사이의 유사도를 측정하며, 값이 낮을수록 답변이 다양하다는 뜻입니다. **Pure Sampling(0.28)**이 가장 다양합니다.
- Repetition % (반복률): 동일한 단어나 문구를 반복하는 비율입니다. **Greedy(73.66%)**는 매우 심각한 반복 문제를 보이지만, **Nucleus Sampling(0.36%)**은 사람(0.28%)과 유사한 수준으로 반복을 제어합니다.
이미지 요약 인사이트:
이 자료의 핵심은 **"어떤 디코딩 방식을 쓰느냐에 따라 LLM의 성격이 완전히 달라진다"**는 점입니다. 단순히 확률이 높은 단어만 고르는 방식(Greedy)은 반복의 늪에 빠지기 쉬우며, **Nucleus Sampling($p=0.95$)**과 같은 정교한 샘플링 기법을 사용해야만 비로소 사람과 유사하게 자연스럽고 중복 없는 문장을 생성할 수 있음을 입증합니다.


자유 형식 텍스트 생성의 평가지표 (Metrics for Open-ended Text Generation)
텍스트 생성 모델의 품질을 객관적으로 평가하기 위해 수학적 확률 기반의 지표와 인간의 주관적 기준 사이의 균형을 맞추는 것이 중요합니다.
1. Perplexity (PPL, 당혹도)
- 정의: 모델이 단어의 시퀀스를 얼마나 잘 예측하는지를 나타내는 수치입니다.
- 계산 방식: 다음 단어가 나타날 확률의 역수를 기하평균하여 산출합니다.
- 특성:
- 확률값은 생성 모델(LLM) 자체에서 얻거나, 외부의 평가용 LLM을 통해 얻을 수 있습니다.
- 값이 낮을수록 모델의 예측 성능(품질)이 더 뛰어남을 의미합니다.
- 주의사항: 수학적으로 낮은 Perplexity가 반드시 사람이 느끼는 텍스트의 품질과 항상 일치하는 것은 아닙니다.
2. 다각도 평가의 필요성과 한계
- 평가 기준: 단순 예측력을 넘어 명확성(Clarity), 일관성(Coherence), 창의성(Creativity) 등 다양한 기준이 존재합니다.
- 단일 점수화의 어려움: 이러한 다양한 요소들을 개별적으로 계산하는 것이 아니라, 하나의 종합 점수로 통합하여 평가하고자 하는 요구가 큽니다.
- 비용의 문제: 인간 평가자(Human annotator)를 고용하는 것이 가장 정확하지만, 비용과 시간이 너무 많이 든다는 치명적인 단점이 있습니다.
종합 요약 및 마무리: 이 자료의 핵심은 **"모델의 실력(Perplexity)과 사람이 느끼는 가치 사이의 간극을 어떻게 메울 것인가"**에 대한 화두를 던지는 것입니다.
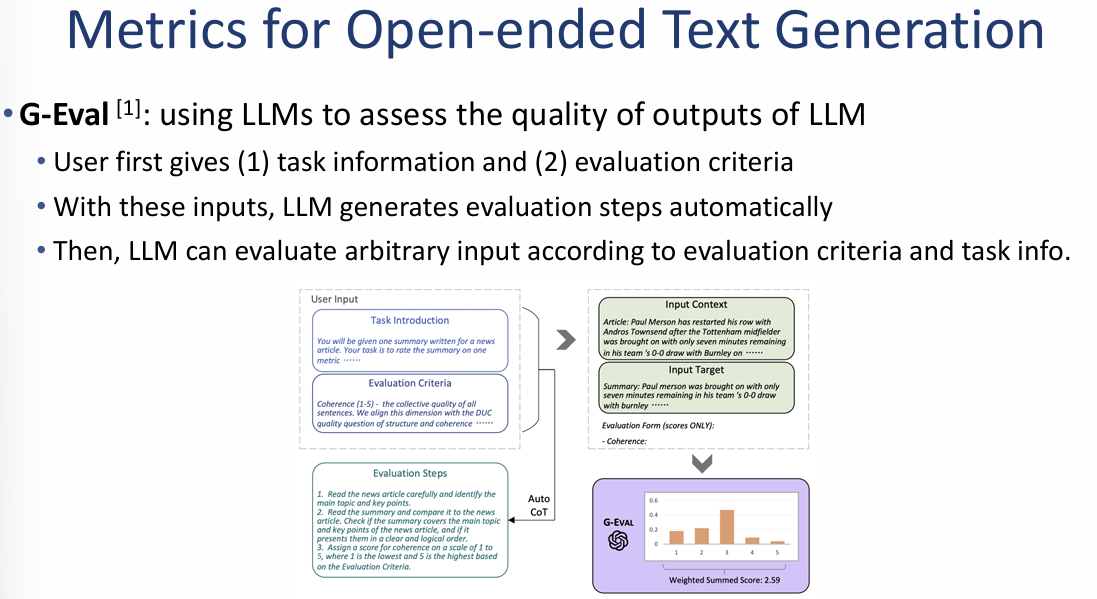

G-Eval: LLM을 활용한 생성 품질 평가 프레임워크
G-Eval은 텍스트 생성 결과물의 품질(명확성, 일관성 등)을 평가하기 위해 사람이 아닌 **거대 언어 모델(LLM)**을 평가자로 사용하는 방식입니다.
1. G-Eval의 작동 원리 (Workflow)
- 입력 정보 제공: 사용자로부터 (1) 수행 태스크 정보와 (2) 구체적인 평가 기준을 입력받습니다.
- 평가 단계 자동 생성 (Auto-CoT): 입력된 정보를 바탕으로 LLM이 어떻게 평가할지에 대한 **세부 평가 단계(Evaluation steps)**를 스스로 생성합니다.
- 임의 입력 평가: 생성된 단계를 따라 모델이 입력된 텍스트를 분석하고 점수를 매깁니다.
2. 주요 특징 및 우수성
- 높은 상관관계: 특히 GPT-4를 평가자로 사용한 G-Eval은 **인간의 평가 결과와 가장 높은 상관관계(highest correlation)**를 보이는 것으로 입증되었습니다.
- 표준화된 접근법: 기존의 ROUGE(단어 중복)나 BERTScore(임베딩 유사도)와 같은 수치적 지표를 넘어, 특정 기준을 가진 LLM을 평가자로 활용하는 방식이 현재의 표준적인 접근법으로 자리 잡았습니다.
- 프롬프트 구성: 이미지 우측 하단에는 실제 LLM을 채점 모델로 사용할 때 필요한 구체적인 채점 가이드(Scoring model prompt) 예시가 제시되어 있습니다.
종합 요약 및 마무리: 이 자료의 핵심은 **"가장 정확한 평가자인 사람을 대신해, 사람과 가장 비슷하게 사고하는 GPT-4 같은 모델에게 평가를 맡기자"**는 것입니다. 이는 평가 비용을 획기적으로 줄이면서도 주관적이고 추상적인 품질 기준까지 놓치지 않는 고도의 평가 전략을 보여줍니다.
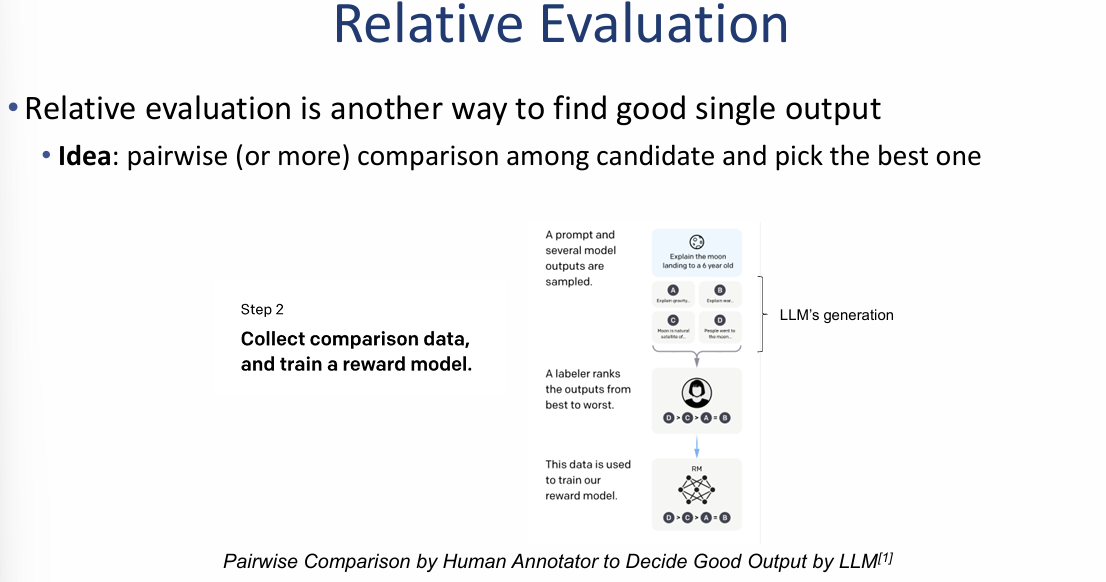

상대적 평가 (Relative Evaluation)
이 자료는 모델의 결과물을 단독으로 평가하는 대신, 여러 후보군을 서로 비교하여 최적의 답변을 찾아내는 상대적 평가 방법론과 그 대표 사례를 다루고 있습니다.
1. 핵심 개념 및 프로세스 (Idea)
- 비교 평가: 단일 출력물을 절대 평가하는 것이 아니라, 여러 개의 생성 후보(Candidate)들 사이에서 쌍별 비교(Pairwise comparison) 또는 그 이상의 다자간 비교를 통해 가장 좋은 것을 선택합니다.
- 학습 단계:
- 동일한 프롬프트에 대해 여러 모델의 출력 샘플을 수집합니다.
- 전문 라벨러(Human annotator)가 해당 출력물들의 순위를 매깁니다.
- 이 순위 데이터를 활용하여 인간의 선호도를 학습한 **보상 모델(Reward model)**을 훈련시킵니다.
2. 대표 사례: Chatbot Arena
이미지는 LLM 성능 비교에서 가장 신뢰받는 지표 중 하나인 Chatbot Arena의 실제 리더보드를 보여줍니다.
- 특징: 실제 사용자의 피드백을 기반으로 하는 가장 신뢰도 높은 비교 방식 중 하나로 평가받습니다.
- 리더보드 순위 (이미지 기준):
- 1위: Gemini 1.5 Pro (Experimental)
- 2위: GPT-4o
- 3위: Claude 3.5 Sonnet
- 지표: 각 모델은 Elo Rating을 기반으로 점수가 산정되며, 이를 통해 전 세계 모델들의 상대적인 순위를 실시간으로 확인할 수 있습니다.
요약 인사이트: 이 자료의 핵심은 모델의 성능을 단순히 점수화하는 것을 넘어, **"사람이 보기에 어떤 답변이 더 좋은가"**를 집단지성과 비교 시스템을 통해 검증하는 것이 가장 정확한 평가 지표가 될 수 있음을 보여줍니다.
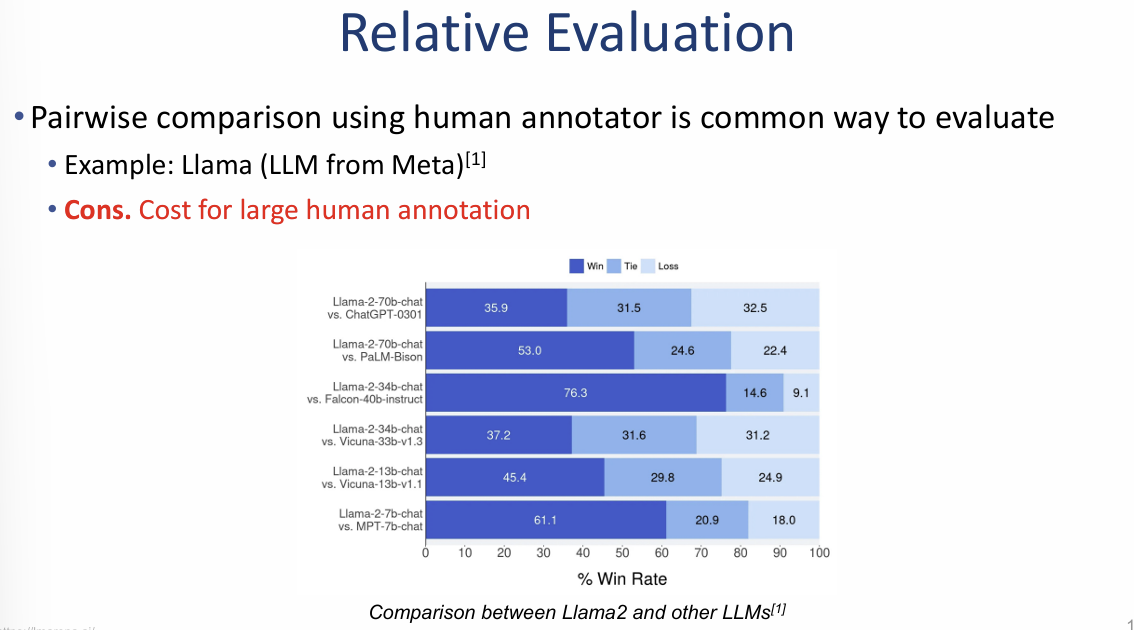
상대적 평가: 인간 주석자를 활용한 쌍별 비교
이 방식은 두 모델의 답변을 나란히 놓고 사람이 어떤 것이 더 우수한지 직접 판단하게 함으로써, 수치적 지표(ROUGE, BLEU 등)가 잡아내지 못하는 언어의 미묘한 품질 차이를 평가합니다.
1. 평가 사례: Llama (Meta의 거대 언어 모델)
이미지의 그래프는 Meta에서 출시한 Llama 2 모델과 다른 경쟁 모델들(ChatGPT, PaLM, Vicuna 등) 간의 승률(Win Rate) 비교 결과를 보여줍니다.
- 비교 방식: 인간 주석자(Human annotator)들이 두 모델의 답변을 보고 **승(Win), 무(Tie), 패(Loss)**를 결정합니다.
- 주요 결과:
- Llama-2-70b-chat은 ChatGPT-0301 모델과 대등한 수준(승리 35.9% vs 패배 32.5%)의 성능을 보입니다.
- Falcon-40b-instruct 모델과의 비교에서는 **76.3%**라는 압도적인 승률을 기록하며 성능 우위를 입증했습니다.
2. 상대적 평가의 치명적인 단점 (Cons)
- 높은 비용 (Cost): 대규모의 인간 주석 데이터를 수집하는 데 드는 비용과 시간이 매우 막대합니다.
- 확장성 부족: 새로운 모델이 나올 때마다 매번 사람을 고용해 비교 작업을 반복해야 하므로 시스템을 확장하기가 어렵습니다.
종합 요약 및 마무리: 이 자료는 **"사람의 판단이 가장 정확한 기준이지만, 그 과정이 너무 비싸고 느리다"**는 인공지능 평가의 핵심 딜레마를 보여줍니다. 이러한 문제를 해결하기 위해 앞서 살펴본 Chatbot Arena와 같은 집단지성 플랫폼이나, G-Eval처럼 LLM이 사람 대신 평가하는 기술들이 등장하게 되었습니다.


MT-Bench: 멀티턴 대화 능력 평가의 표준
기존의 단답형 평가(MMLU 등)와 달리, 챗봇이 실제 사용자와 대화하듯 맥락을 유지하며 답변을 이어가는 능력을 측정하기 위해 설계된 벤치마크입니다.
- 데이터셋 구성: 롤플레잉, 수학, 코딩, 글쓰기 등 8개 카테고리에서 엄선된 80개의 고품질 멀티턴(Multi-turn) 질문으로 이루어져 있습니다.
- 평가 시나리오: 이미지 좌측 하단의 예시처럼, 모델에게 특정 인물(예: 일론 머스크)이 되어 대화하도록 시킨 뒤, 이어지는 후속 질문에도 일관된 페르소나와 맥락을 유지하는지 확인합니다.
GPT-4 심판과 인간의 높은 일치도 (High Agreement)
이 자료의 가장 중요한 포인트는 **"강력한 LLM(GPT-4)이 내린 평가가 실제 인간 전문가의 판단과 매우 유사하다"**는 사실을 데이터로 증명한 것입니다.
- 일치율 수치: 이미지 우측 표를 보면, 무승부(Tie)를 제외한 설정(S2)에서 **GPT-4와 인간의 일치율은 85%**에 달합니다.
- 비교 데이터: 이는 인간 평가자들끼리의 일치율(81%)보다도 높은 수치로, GPT-4가 다수의 인간 선호도를 매우 정확하게 대변할 수 있음을 의미합니다.
- 판정의Affirmative성: GPT-4는 다른 심판 모델들에 비해 무승부보다 명확한 승패 판정을 내리는 경향이 있으며, 위치 편향에도 상대적으로 덜 민감합니다.
이미지 요약 인사이트: 이 자료는 MT-Bench를 통해 **"LLM을 심판으로 쓰는 것이 단순히 빠르고 싼 대안이 아니라, 인간의 기준과 매우 부합하는 신뢰할 수 있는 방법론"**임을 강조합니다.


LLM-as-Judge: LLM을 활용한 자동 평가 솔루션
인간 주석가(Human annotator)를 고용하는 방식의 막대한 비용과 확장성 문제를 해결하기 위해, 고성능 LLM을 심판으로 활용하는 전략입니다.
1. 핵심 개념 (Idea)
- 인간 대체: 사람이 직접 답변의 순위를 매기는 대신, LLM에게 두 모델의 답변을 보여주고 어떤 것이 더 나은지 판단하도록 프롬프팅합니다.
- 평가 프로세스:
- 시스템 프롬프트를 통해 LLM에게 '공정한 심판'의 역할을 부여합니다.
- 도움말의 유용성, 관련성, 정확성, 깊이 등을 기준으로 두 답변을 비교하도록 지시합니다.
- 최종적으로 어느 쪽이 더 나은지([[A]], [[B]]) 혹은 비겼는지([[C]]) 판정 결과를 출력합니다.
2. 주요 장점 (Key Advantages)
- 확장성(Scalability): 사람이 직접 하는 것보다 훨씬 빠르고 저렴하게 수만 건의 데이터를 평가할 수 있습니다.
- 설명 가능성(Explainability): 단순히 점수만 매기는 것이 아니라, 왜 해당 답변이 더 우수한지에 대한 구체적인 근거와 이유(Reasoning)를 함께 제시할 수 있습니다.
3. GPT-4 심판 활용 예시
이미지 우측에는 GPT-4가 두 조수(Assistant A, B)의 답변을 심사하는 실제 사례가 나와 있습니다.
- 판정 내용: Assistant A의 답변이 반복적이고 구체적인 사례가 부족하다는 점을 지적하며, 더 관련성 있고 상세한 사례를 제공한 Assistant B의 손을 들어줍니다.
- 효과: 이를 통해 모델 개발자는 어떤 부분에서 답변의 품질이 떨어지는지 즉각적인 피드백을 받을 수 있습니다.
종합 요약 및 마무리: 이 자료의 핵심은 **"성능이 뛰어난 모델이 하위 모델의 선생님이자 심판이 되는 구조"**를 설명하는 것입니다. 특히 현재 진행 중이신 법률/특허 챗봇 프로젝트에서 답변의 신뢰성을 검증할 때, 매번 사람이 검수하기 어렵다면 이 LLM-as-Judge 방식을 도입하여 평가 자동화 파이프라인을 구축하는 것이 가장 현실적이고 효율적인 대안이 될 것입니다.

LLM-as-Judge의 한계: 모델 평가 시 발생하는 편향 (Caution)
고성능 LLM이 심판 역할을 수행할 때, 인간과는 다른 고유한 판단 오류를 범할 수 있으므로 주의가 필요합니다.
1. 3가지 주요 편향 (Three Key Biases)
- 위치 편향 (Position bias): 답변의 내용과 상관없이 특정 위치(예: 첫 번째로 제시된 답변)를 더 선호하는 경향이 있습니다.
- 장황함 편향 (Verbosity bias): 답변이 명확하거나 고품질이 아니더라도, 단순히 길게 작성된 답변에 더 높은 점수를 주는 경향이 있습니다.
- 자기 선호 편향 (Self-preference bias): 평가 모델 자신이 생성한 답변과 유사한 스타일이나 내용을 더 높게 평가하는 경향이 있습니다.
2. 실험 데이터 분석 (Experiments that reveal biases)
이미지 하단의 그래프는 GPT-4, GPT-3.5, Claude 등 주요 모델들이 심판으로 나섰을 때 인간의 평가와 어떻게 다른지 보여줍니다.
- 자기 선호 현상: 각 모델 심판들은 일반적으로 자신과 같은 계열의 모델에게 더 높은 승률(Win rate)을 부여하는 양상을 보입니다.
- 인간과의 격차: 인간(Human)의 평가 곡선과 각 모델 심판들의 곡선 사이에 간극이 존재하며, 이는 모델이 인간의 선호도를 완벽히 복제하지 못한다는 것을 의미합니다.
종합 요약 및 마무리: 이 자료의 핵심은 **"심판(LLM)도 완벽하지 않으며, 자기중심적이거나 겉보기에 긴 답변에 속을 수 있다"**는 점을 경고하는 것입니다.


LLM-as-Judge: 주요 편향에 대한 기술적 솔루션
모델 심판의 주관적인 오류를 최소화하고 평가의 객관성을 높이기 위해 다음과 같은 보정 기법들을 사용합니다.
1. 위치 편향(Position Bias) 해결책
- 방법: 두 모델의 답변 위치를 서로 바꾸어 **두 번의 평가(Swapped positions)**를 진행합니다.
- 판정: 예를 들어 첫 번째 평가에서 A가 승리하고, 위치를 바꾼 두 번째 평가에서 B가 승리했다면 이를 **'무승부(Tied)'**로 평균을 내어 처리합니다.
- 단점: 동일한 데이터에 대해 평가를 두 번 수행해야 하므로 비용이 2배로 발생합니다.
2. 장황함 편향(Verbosity Bias) 해결책
- 방법: 답변의 길이에 따른 유리함을 제거하기 위해 길이 조정 승률(LC Win Rate, Length-Controlled Win Rate) 지표를 도입합니다.
- 구현 사례 (AlpacaEval): GPT-4를 심판으로 사용하는 AlpacaEval 리더보드에서는 답변의 정렬(Alignment) 능력을 평가할 때 답변 길이의 영향을 배제하는 로직을 적용합니다.
- 수식 원리: 모델의 고유 성능($\theta$)과 답변의 길이($len$) 사이의 상관관계를 통계적 함수(logistic, tanh 등)로 모델링하여, 단순히 길다는 이유로 높은 점수를 받는 왜곡을 수학적으로 보정합니다.
종합 요약 및 인사이트:
이 자료의 핵심은 **"심판의 편향을 인지하는 수준을 넘어, 수학적·절차적 장치를 통해 이를 강제로 보정하는 방법"**을 보여주는 것입니다. 특히 위치를 바꿔 두 번 검증하거나 길이 가중치를 제거하는 방식은 실제 서비스에서 자동 평가 시스템의 신뢰도를 확보하는 데 필수적인 기술입니다.
- wsl에 아래 명령어 실행
curl -fsSL https://ollama.com/install.sh | sh
- 설치 이후 버전확인
ollama --version
curl http://localhost:11434
ollama run llama3

systemd는 리눅스 시스템의 서비스와 프로세스를 관리하는 시스템 초기화(boot) 및 서비스 매니저입니다.
WSL2에서는 기본적으로 systemd가 비활성화되어 있습니다.
sudo nano /etc/wsl.conf
[boot]
systemd=true
wsl --shutdown
wsl2가 아니거나 해결이 안되는경우

WSL1은 systemd를 지원하지 않기 때문에, Ollama처럼 systemd 기반으로 백그라운드 서비스(데몬)를 구동하는 방식은 사용할 수 없다 wsl2로 바꾸고싶다면 wsl --set-version Ubuntu 2

터미널 1
ollama serve
터미널2
ollama run llama2
나중에 터미널 꺼도 서버는 계속 돌고, 로그도 남아 있어서 안심하고 쓸 수 있어요
nohup ollama serve > ollama.log 2>&1 &

4비트 양자화와 2차 양자화
-파라미터를 가볍게 만들어서 용량 축소 but 성능 down
페이지 옵티마이저 통합 메모리를 통해 GPU가 CPU 메모리(RAM)를 공유하는것을 말함
페이징이란 필요한 작업을 교체하는것..?
교체 주기가 너무 많아 오버헤드 걸린다...라는의미
바닐라 모델 성능을 비교하는 모델
sys를 통해서 아큐먼트를 전달
오늘 정리하신 코드는 꽤 많은 단계를 거친 한국어 Text-to-SQL 모델 평가 및 LoRA 파인튜닝 자동화 전체 파이프라인입니다.
한마디로 말하면,
**“한국어 질문(자연어)과 DDL(데이터베이스 정의)를 받아 적절한 SQL을 생성하는 모델을 평가하고, 나아가 LoRA 방식으로 직접 파인튜닝까지 수행하는 전 과정을 자동화한 스크립트 모음”**이에요.
목적:
- Hugging Face 모델(beomi/Yi-Ko-6B)을 활용해 한국어 SQL 생성 모델을 평가
- LoRA 방식으로 파인튜닝 수행
랭체인 기본 구조
primpt | llm | StrOutputParser
'AI > LLM' 카테고리의 다른 글
| [PEFT 1] 효율적 튜닝 LoRA (0) | 2025.07.29 |
|---|---|
| [RLHF] 인간의 가치 정렬 (0) | 2025.07.25 |
| [Pre-training] 거대한 지식의 축적 (0) | 2025.07.23 |
| [Tokenizer] 언어를 쪼개는 기술 (0) | 2025.07.22 |
| [In-Context Learning] 맥락의 힘 (0) | 2025.07.21 |